
In the rapidly evolving field of artificial intelligence, selecting the best AI models from a plethora of available options can be a daunting task. This study aims to facilitate the decision-making process by providing an in-depth comparative study of AI model types and selection criteria. Understanding the differences among the top-performing artificial intelligence models is crucial for anyone looking to harness the power of machine learning in their applications.
By examining how to choose AI models based on their training data, performance, lexical density, readability, and other evaluation metrics, you will gain a comprehensive understanding of each model's strengths and weaknesses. With these insights, you can confidently select the best AI models tailored to your specific needs and build cutting-edge applications that capitalize on the advances in artificial intelligence and machine learning.
Co:here, GPT-3.5, GPT-3.5 Turbo, GPT-4, Google Bard, Hugging Chat, StableLM, MosaicML
Generative AI, Natural Language Generation, and Long Language Models (LLM) are currently at the forefront of AI, demonstrating unprecedented capabilities in generating human-like text. Applied to the tasks of content production, Q&A chatbots, and other cases, they have opened up new dimensions for creative expression.
For this brief comparative study some of the most popular AI / LLM were chosen: GPT-4, GPT-3.5 Turbo, GPT-3.5, Google Bard, Co:here Generate, and recently releeased Hugging Chat, StableLM, and MosaicLM.
Study Purpose
This study is aimed to compare these AI models' outcomes without taking into account datasets, quantity of parameters or other characteristics. This study is focused on finding similarities and differences in outcomes, and as a result - on an objective assessment of performances of each of the models.
Metrics
The following metriscs are used for comparison and calculions done using the Python NLTK and Readability libraries the Seaborn library is used for visualisations.
Lexical density: Lexical density refers to the proportion of unique words to the total words in a text. It is crucial in comparing language models as a higher lexical density indicates a richer vocabulary and better content quality. It also reflects how well a language model can maintain variety in its expressions. To compute the lexical diversity, the ratio of unique words to the total words of the generated texts is used.
Readability score: This metric evaluates the ease with which a reader can comprehend a text. It is vital in language model comparisons to ensure that the generated content is appropriate for the target audience. A high readability score suggests that the text is easily understandable with proper sentence structure and vocabulary, making it accessible and user-friendly. This metric is based on the Flesch Reading Ease Score from Readability Library in Python. The Flesch Reading Ease score is a crucial metric for assessing the readability of LLM models as it provides an objective measure of the text's simplicity and clarity. The score ranges from 0 to 100, and it is calculated based on sentence length and word complexity. Higher scores indicate that the text is easier to read and understand, while lower scores imply that the content is more challenging.
Amount of generated content or quantity of words: This metric is important as it indicates the capacity of language models in generating comprehensive text. A model with higher word generation capability typically provides more extensive and detailed content, offering diverse options for users. The number of words in the generated texts is determined using the Python NLTK word_tokenize() and the len() functions.
To assessment of performance is made based on the the same prompt: "generate a blog post about lexical diversity ratio" sent to the Co:here Generate, GPT-3.5, GPT-3.5 Turbo, and GPT-4 models using IngestAI.io platform and websites of Google Bard and Hugging Face for Hugging Chat, MosaicLM, and StableLM.
In [4]:
import nltk
import pandas as pd
from nltk import word_tokenize, sent_tokenize
from readability import Readability
import plotly.graph_objects as goIn [5]:
def analyze_text(text):
r = Readability(text)
minimal_age = r.flesch().score
tokens = word_tokenize(text)
text_len = len(tokens)
unique_words = len(set(tokens))
lexical_diversity = unique_words / text_len
ease = r.flesch().ease
print("\n Number of words:", text_len, "\n Lexical diversity:", "%.2f" % lexical_diversity,
"\n Readability Score", "%.0f" % minimal_age ,"->", ease)Co:here
The model is trained using large corpora of text data and is designed to be flexible and capable of generating a wide variety of output. The Cohere generate model is a general purpose language model that can be used for a variety of tasks, including text generation, language translation, and natural language processing.
Try it on IngestAI http://ingestai.io or CoherePlayground https://dashboard.cohere.ai/playground/generate
In [6]:
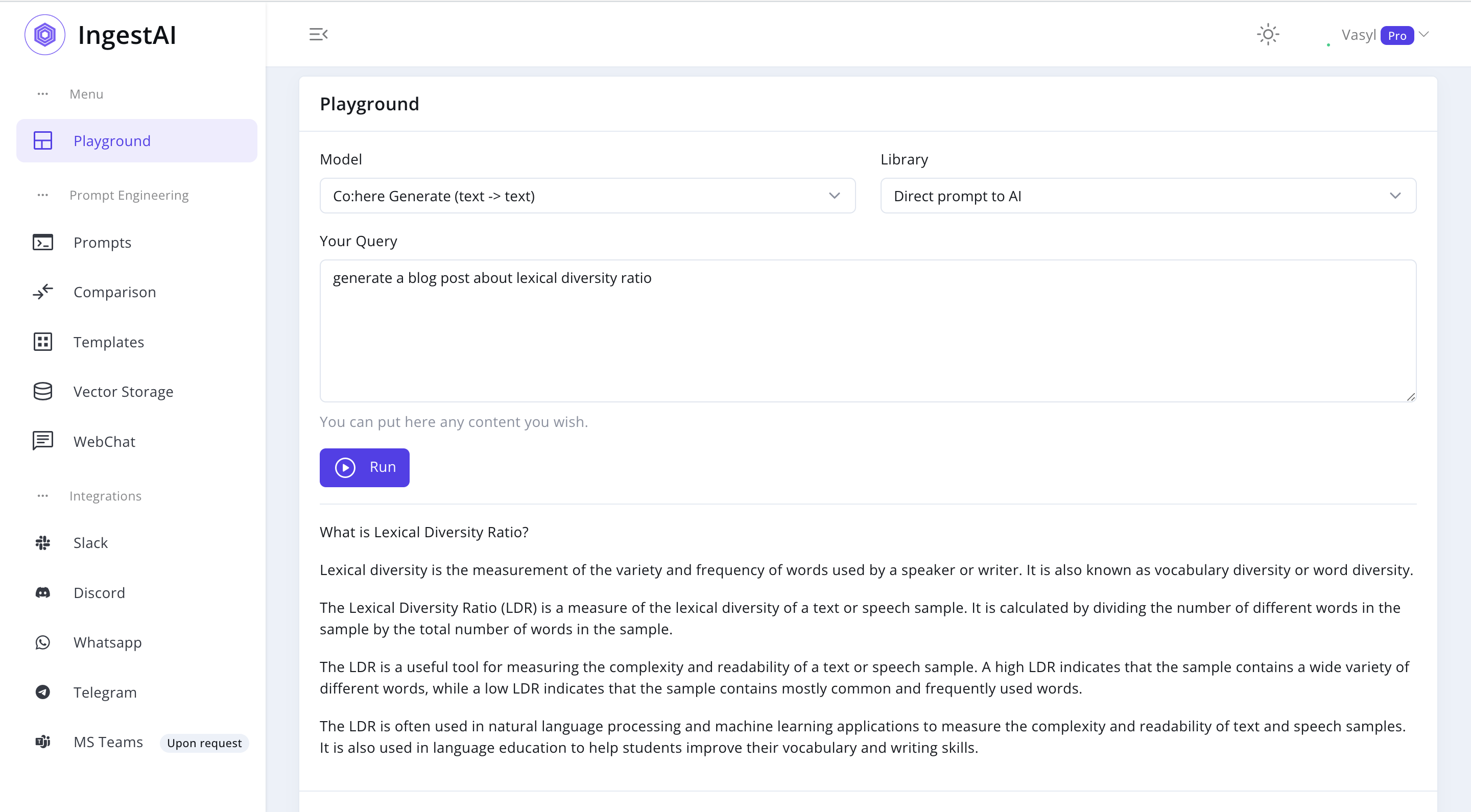
Cohere = '''What is Lexical Diversity Ratio? Lexical diversity is the measurement of the variety and frequency of words used by a speaker or writer. It is also known as vocabulary diversity or word diversity. The Lexical Diversity Ratio (LDR) is a measure of the lexical diversity of a text or speech sample. It is calculated by dividing the number of different words in the sample by the total number of words in the sample. The LDR is a useful tool for measuring the complexity and readability of a text or speech sample. A high LDR indicates that the sample contains a wide variety of different words, while a low LDR indicates that the sample contains mostly common and frequently used words. The LDR is often used in natural language processing and machine learning applications to measure the complexity and readability of text and speech samples. It is also used in language education to help students improve their vocabulary and writing skills.'''In [7]:
analyze_text(Cohere) Number of words: 172
Lexical diversity: 0.44
Readability Score 40 -> difficultThis model produced a moderately short response with 172 words and a lexical diversity of 0.44, indicating a fair variety of vocabulary. Its readability score of 40 implies that the text is somewhat challenging to read.
GPT-3.5
The GPT-3.5 model is an enhanced adaptation of the GPT-3 (Generative Pre-trained Transformer) model, having been fine-tuned and introduced in January 2022. As a neural network-based language model, GPT-3.5 benefits from an extensive training on an immense data set.
Try it on IngestAI http://ingestai.io or OpenAI Playground https://platform.openai.com/playground
In [8]:
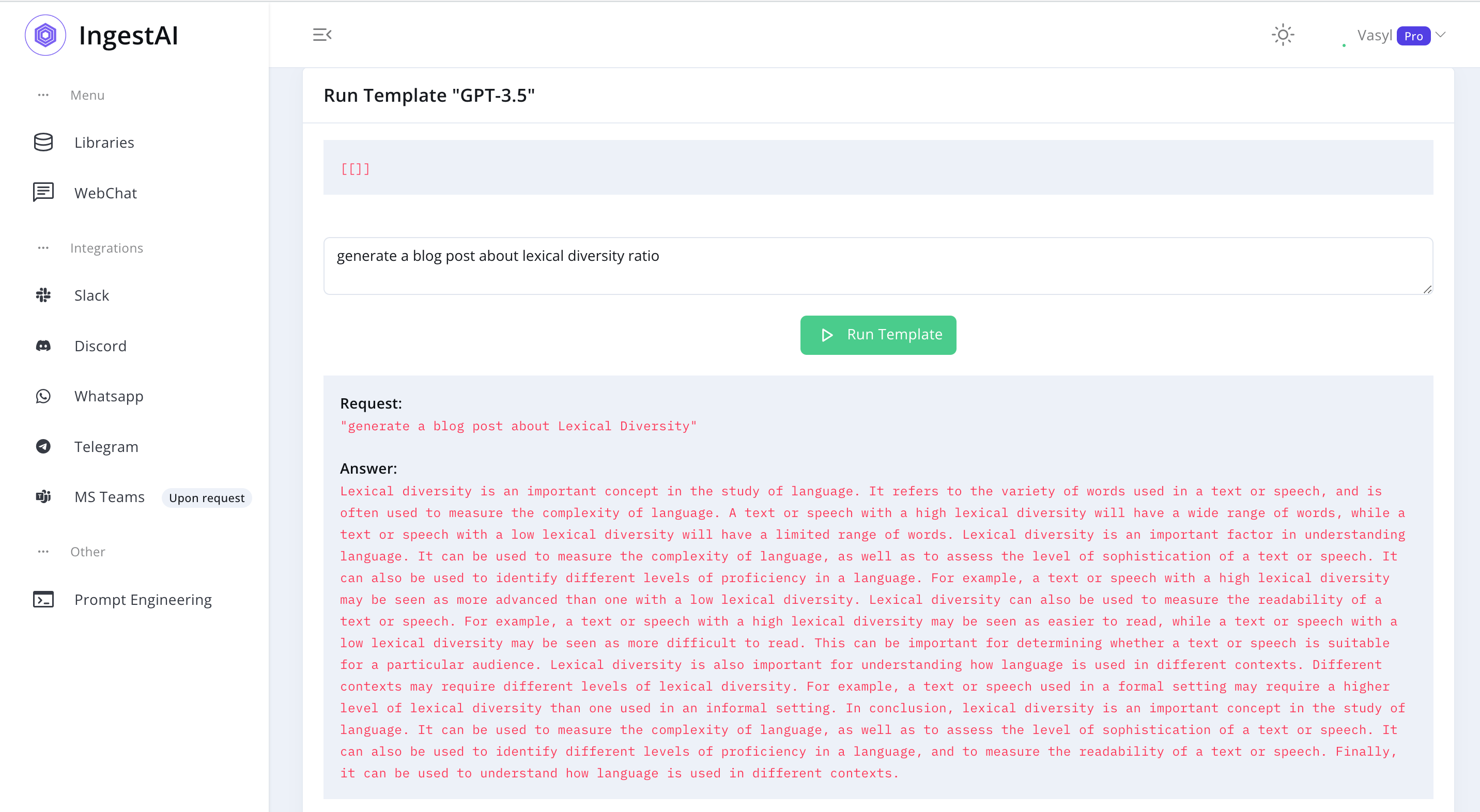
GPT_3_5 = '''Lexical diversity is an important concept in the study of language. It refers to the variety of words used in a text or speech, and is often used to measure the complexity of language. A text or speech with a high lexical diversity will have a wide range of words, while a text or speech with a low lexical diversity will have a limited range of words. Lexical diversity is an important factor in understanding language. It can be used to measure the complexity of language, as well as to assess the level of sophistication of a text or speech. It can also be used to identify different levels of proficiency in a language. For example, a text or speech with a high lexical diversity may be seen as more advanced than one with a low lexical diversity. Lexical diversity can also be used to measure the readability of a text or speech. For example, a text or speech with a high lexical diversity may be seen as easier to read, while a text or speech with a low lexical diversity may be seen as more difficult to read. This can be important for determining whether a text or speech is suitable for a particular audience. Lexical diversity is also important for understanding how language is used in different contexts. Different contexts may require different levels of lexical diversity. For example, a text or speech used in a formal setting may require a higher level of lexical diversity than one used in an informal setting. In conclusion, lexical diversity is an important concept in the study of language. It can be used to measure the complexity of language, as well as to assess the level of sophistication of a text or speech. It can also be used to identify different levels of proficiency in a language, and to measure the readability of a text or speech. Finally, it can be used to understand how language is used in different contexts.'''In [9]:
analyze_text(GPT_3_5) Number of words: 358
Lexical diversity: 0.23
Readability Score 46 -> difficultThis model generated a longer text with 358 words, offering a relatively lower lexical diversity of 0.23. The readability score is 46, making the text easier to read compared to the Cohere model.
GPT-3.5 Turbo
he GPT-3.5 Turbo is the most efficient and economical model within the GPT-3.5 family. Optimized for chat-based applications, it also excels in conventional completion tasks. Launched on March 1st, 2023, GPT-3.5 Turbo outperforms its predecessors, GPT-3.5 and GPT-3 Davinci, with enhanced capabilities.
Try it on IngestAI http://ingestai.io or OpenAI Playground https://platform.openai.com/playground
In [10]:
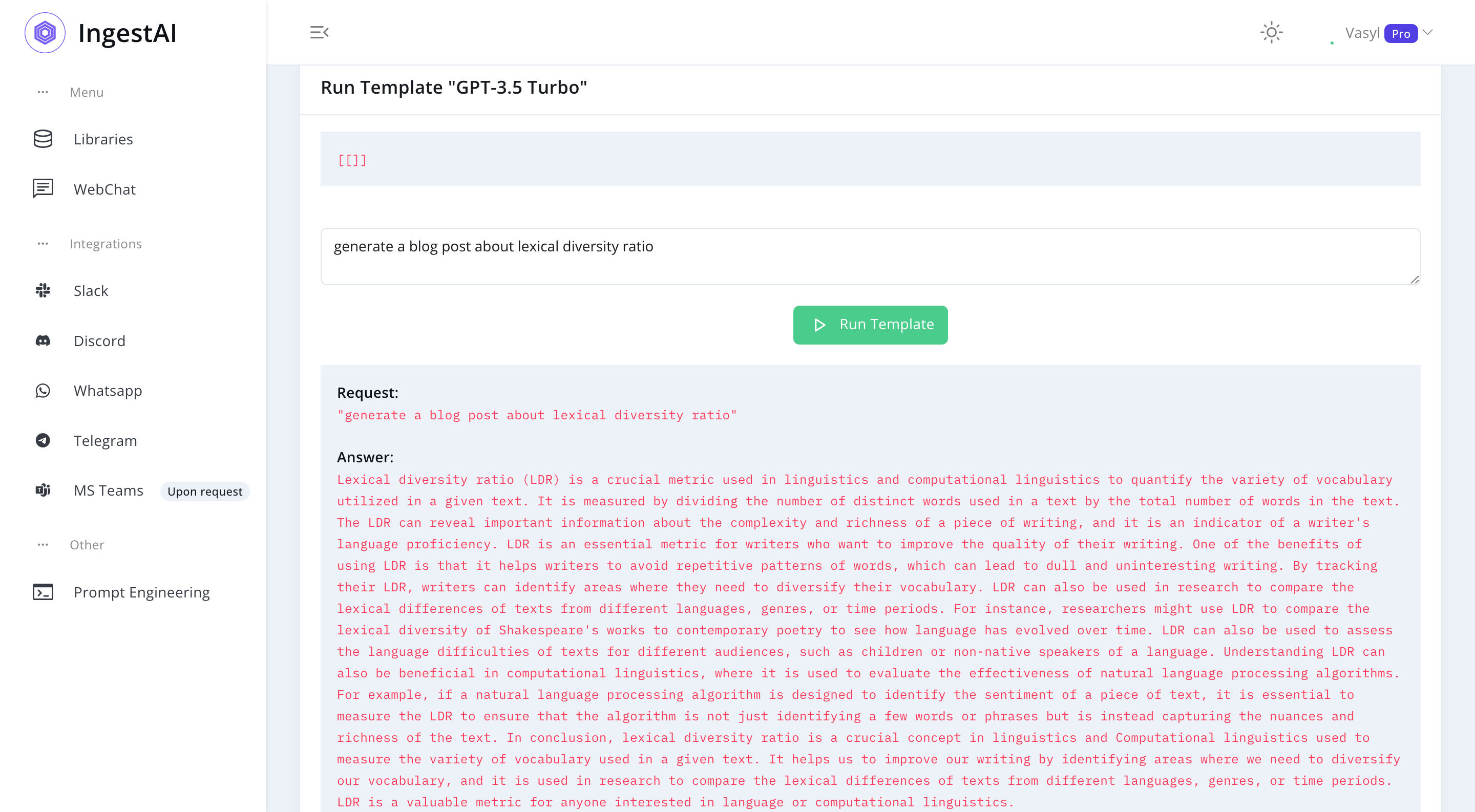
GPT_3_5_Turbo = '''Lexical diversity ratio (LDR) is a crucial metric used in linguistics and computational linguistics to quantify the variety of vocabulary utilized in a given text. It is measured by dividing the number of distinct words used in a text by the total number of words in the text. The LDR can reveal important information about the complexity and richness of a piece of writing, and it is an indicator of a writer's language proficiency. LDR is an essential metric for writers who want to improve the quality of their writing. One of the benefits of using LDR is that it helps writers to avoid repetitive patterns of words, which can lead to dull and uninteresting writing. By tracking their LDR, writers can identify areas where they need to diversify their vocabulary. LDR can also be used in research to compare the lexical differences of texts from different languages, genres, or time periods. For instance, researchers might use LDR to compare the lexical diversity of Shakespeare's works to contemporary poetry to see how language has evolved over time. LDR can also be used to assess the language difficulties of texts for different audiences, such as children or non-native speakers of a language. Understanding LDR can also be beneficial in computational linguistics, where it is used to evaluate the effectiveness of natural language processing algorithms. For example, if a natural language processing algorithm is designed to identify the sentiment of a piece of text, it is essential to measure the LDR to ensure that the algorithm is not just identifying a few words or phrases but is instead capturing the nuances and richness of the text. In conclusion, lexical diversity ratio is a crucial concept in linguistics and Computational linguistics used to measure the variety of vocabulary used in a given text. It helps us to improve our writing by identifying areas where we need to diversify our vocabulary, and it is used in research to compare the lexical differences of texts from different languages, genres, or time periods. LDR is a valuable metric for anyone interested in language or computational linguistics.'''In [11]:
analyze_text(GPT_3_5_Turbo)
Number of words: 382
Lexical diversity: 0.39
Readability Score 33 -> difficultWith 382 words, this model's output was similar in length to GPT-3.5, but had a higher lexical diversity of 0.39. However, the lower readability score of 33 suggests that the text might be more difficult to understand.
GPT-4
GPT-4 represents the most recent iteration of Generative Pre-trained Transformers, a sophisticated deep learning model designed for natural language processing and text generation tasks. This innovation serves as a notable advancement in the realm of artificial intelligence, especially within the domain of natural language processing.
Try it on IngestAI http://ingestai.io or OpenAI https://chat.openai.com
In [12]:
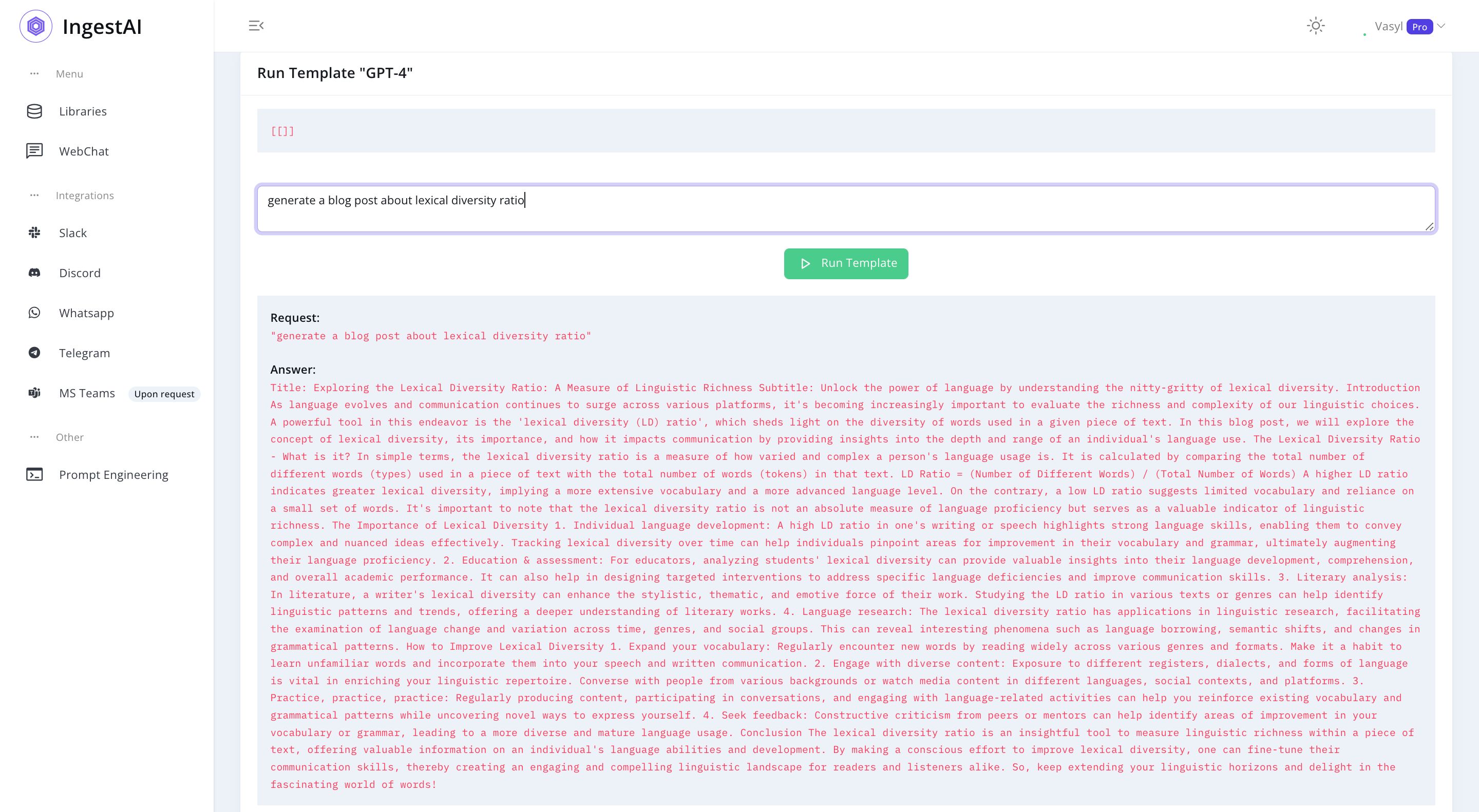
GPT_4 = '''Title: Exploring the Lexical Diversity Ratio: A Measure of Linguistic Richness Subtitle: Unlock the power of language by understanding the nitty-gritty of lexical diversity. Introduction As language evolves and communication continues to surge across various platforms, it's becoming increasingly important to evaluate the richness and complexity of our linguistic choices. A powerful tool in this endeavor is the 'lexical diversity (LD) ratio', which sheds light on the diversity of words used in a given piece of text. In this blog post, we will explore the concept of lexical diversity, its importance, and how it impacts communication by providing insights into the depth and range of an individual's language use. The Lexical Diversity Ratio - What is it? In simple terms, the lexical diversity ratio is a measure of how varied and complex a person's language usage is. It is calculated by comparing the total number of different words (types) used in a piece of text with the total number of words (tokens) in that text. LD Ratio = (Number of Different Words) / (Total Number of Words) A higher LD ratio indicates greater lexical diversity, implying a more extensive vocabulary and a more advanced language level. On the contrary, a low LD ratio suggests limited vocabulary and reliance on a small set of words. It's important to note that the lexical diversity ratio is not an absolute measure of language proficiency but serves as a valuable indicator of linguistic richness. The Importance of Lexical Diversity 1. Individual language development: A high LD ratio in one's writing or speech highlights strong language skills, enabling them to convey complex and nuanced ideas effectively. Tracking lexical diversity over time can help individuals pinpoint areas for improvement in their vocabulary and grammar, ultimately augmenting their language proficiency. 2. Education & assessment: For educators, analyzing students' lexical diversity can provide valuable insights into their language development, comprehension, and overall academic performance. It can also help in designing targeted interventions to address specific language deficiencies and improve communication skills. 3. Literary analysis: In literature, a writer's lexical diversity can enhance the stylistic, thematic, and emotive force of their work. Studying the LD ratio in various texts or genres can help identify linguistic patterns and trends, offering a deeper understanding of literary works. 4. Language research: The lexical diversity ratio has applications in linguistic research, facilitating the examination of language change and variation across time, genres, and social groups. This can reveal interesting phenomena such as language borrowing, semantic shifts, and changes in grammatical patterns. How to Improve Lexical Diversity 1. Expand your vocabulary: Regularly encounter new words by reading widely across various genres and formats. Make it a habit to learn unfamiliar words and incorporate them into your speech and written communication. 2. Engage with diverse content: Exposure to different registers, dialects, and forms of language is vital in enriching your linguistic repertoire. Converse with people from various backgrounds or watch media content in different languages, social contexts, and platforms. 3. Practice, practice, practice: Regularly producing content, participating in conversations, and engaging with language-related activities can help you reinforce existing vocabulary and grammatical patterns while uncovering novel ways to express yourself. 4. Seek feedback: Constructive criticism from peers or mentors can help identify areas of improvement in your vocabulary or grammar, leading to a more diverse and mature language usage. Conclusion The lexical diversity ratio is an insightful tool to measure linguistic richness within a piece of text, offering valuable information on an individual's language abilities and development. By making a conscious effort to improve lexical diversity, one can fine-tune their communication skills, thereby creating an engaging and compelling linguistic landscape for readers and listeners alike. So, keep extending your linguistic horizons and delight in the fascinating world of words!'''In [13]:
analyze_text(GPT_4) Number of words: 724
Lexical diversity: 0.44
Readability Score 23 -> very_confusingThis model had the longest response at 724 words, maintaining a lexical diversity of 0.44. Its readability score of 23 reveals that the text is likely to be quite challenging for readers to comprehend.
Google Bard
Bard is an innovative chatbot developed by Google, utilizing the cutting-edge LaMDA large language model. This generative AI accepts user prompts, adeptly executing text-based tasks such as offering responses, generating summaries, and producing an array of content types.
Try it on: https://bard.google.com
In [14 ]:
Bard = ''' Lexical diversity is a measure of the variety of words used in a text. It is calculated by dividing the number of unique words in a text by the total number of words in the text. A higher lexical diversity ratio indicates a more varied vocabulary. Lexical diversity is important for a number of reasons. First, it can make writing more interesting and engaging to read. When a text uses a variety of words, it can help to keep the reader's attention and prevent the text from becoming monotonous. Second, lexical diversity can improve the clarity of writing. By using a variety of words, writers can avoid using the same word repeatedly, which can make their writing more concise and easier to understand. Third, lexical diversity can be a sign of good writing skills. People who have a large vocabulary are more likely to use a variety of words in their writing, which can make their writing more sophisticated and impressive. There are a number of ways to improve lexical diversity. One way is to read widely. The more you read, the more words you will be exposed to, and the more likely you are to use a variety of words in your own writing. Another way to improve lexical diversity is to use a thesaurus. A thesaurus is a book that lists synonyms and antonyms for words. When you are writing, you can use a thesaurus to find alternative words that have the same meaning as the words you are already using. Finally, you can also improve lexical diversity by simply being aware of the words you use. Pay attention to the words you use in your writing, and try to use a variety of words to express your ideas. Here are some tips for improving lexical diversity: Read widely. The more you read, the more words you will be exposed to. Use a thesaurus. A thesaurus can help you find alternative words that have the same meaning as the words you are already using. Be aware of the words you use. Pay attention to the words you use in your writing, and try to use a variety of words to express your ideas. Lexical diversity is an important part of good writing. By using a variety of words, you can make your writing more interesting, engaging, clear, and sophisticated. '''In [15]:
analyze_text(Bard) Number of words: 437
Lexical diversity: 0.29
Readability Score 60 -> standardThis model's response contained 437 words, offering a lower lexical diversity of 0.29. Yet, its high readability score of 60 indicates quite an easily understandable text.
Hugging Chat
HuggingChat serves as a complimentary, open-source alternative to commercial chat solutions like ChatGPT. Aimed at delivering an AI assistant with an amiable, human-like demeanor, HuggingChat excels in interpreting and responding to inquiries expressed through natural language.
Try it on Hugging Face: https://huggingface.co/chat/
In [16]:
HuggingChat = '''In this article we will discuss the importance of measuring lexical diversity ratio (LDR) in natural language processing tasks. LDR is a metric that reflects the spread or distribution of word frequencies across a corpus. It captures important statistical features of a texts dataset by dividing variance and standard deviation between documents themselves divided by variance among all tokens within documents. Higher scores indicate higher variability among documents and thus diverse use of words among authors. Lower values display opposite patterns of either author imitation and conformity toward one another instead innovation which usually represents lackluster writing. Thus analytics must ensure competitive edge over markets simply through high quality and interesting information for readers where monotonous lists shouldnâââ‰â¢t drive user impressions into ad nauseam boredom that could imply inferior thought processes compared to higher-scoring peers. Acquiring that lead means crafting reward-seeking endorphins driving long term success tied tightly around healthy levels of word replication while ensuring token contrast from document authors. We illustrate difference between polarized and normal LDR distributions to convey clear comparison conclusions where analysis directed at shifting frequency might become necessary against expert oversight. Social media platforms could immediately improve overall posting views by enforcing LDR score thresholds when competing with each other hopefully allowing users thereof find most optimal reading experiences. Facebook, TikTok, Youtube, Twitter and Reddit included would thrive if upping quality standards by using average ratio set above a certain score such as 30 indicating dramatic increase total available posts viewed on their platform. Active enforcement against nonsensical script copy/paste gives superior alternatives priority to enjoy top ranks due highly educated Enforced screening for low ratios threatens massive deleting wave encouraged by fear having accounts totally removed even permanently suspended. Words like purchase, sale, discount and coupon would naturally suffer were filtered out. Never ones opposed driving improved browsing conditions I wish you explored sites maintaining continuously excellent performance versus counterparts remaining static overall without deserved recognition. Anyone experience vast differences in website satisfaction? Author feedback allows indicating alignment towards goal achievement or prevents spiraling failure easily detected analyzing your own writings using obtained online resources open to public allowing anyone discover justification behind incorporating new ideas focused upon surpassing industry norms however personal connection exists. Audiences dictate success beyond their control simply referring LDR into regular conscious focus rather than leaving things subjectively controlled alone greasing gears running on emptiness destined failing miserably daydream believing pleasantly sustainable accomplishment continued thus creating dynamic equilibrium never escaping general importance hereby paving pathways influencing breakaway victories together unless suffering indulgence meeting ultimate fate expressed by closing heartfelt words: Be the force propelling favorable results without suffering any delays! See ya later folks until next time!'''In [17]:
analyze_text(HuggingChat) Number of words: 476
Lexical diversity: 0.83
Readability Score 1 -> very_confusingThis model produced a response with 476 words and a remarkably high lexical diversity of 0.83. However, its very low readability score of 1 implies that the text could be extremely difficult to read.
StableLM Tuned-Alpha-7b Chat
StableLM-Tuned-Alpha-7b Chat refers to a 7B parameter, decoder-only language model that is developed based on the StableLM-Base-Alpha models and is developed by Stability AI. It has been further optimized using an assortment of chat and instruction-following datasets to enhance its performance.
Try it on Hugging Face: https://huggingface.co/spaces/stabilityai/stablelm-tuned-alpha-chat
In [21]:
StableLM = '''A The topic of lexical diversity ratio is an important consideration when working with multi-word language models. This ratio is used to evaluate the performance of a language model on different subsets of the vocabulary. Lexical diversity is the ratio of unique words in the vocabulary of a language model to the total number of words in the vocabulary. It is an important metric because it indicates how well a language model can capture the meaning and context of a language. A lower lexical diversity ratio can be seen as better, but a higher ratio can still be useful in certain cases. In this blog post, we will discuss the concept of lexical diversity ratio and its importance in evaluating the performance of a language model. We will also provide examples of different use cases for this ratio, such as determining the relevance of a document to a query or selecting the best candidates for a recommendation system. B Introduction to lexical diversity ratio * Definition of lexical diversity ratio * Importance of lexical diversity ratio in evaluating language model performance * Key factors and ratios used in lexical diversity ratio C Definitions of lexical diversity ratio * Total number of unique words in the vocabulary * Total number of distinct words in the vocabulary * Total number of unique combinations of a set of words * Total number of documents in the vocabulary 1.1 Lexical diversity ratio A good language model should have a low lexical diversity ratio, which is often defined as: * Total number of unique words in the vocabulary * Total number of distinct words in the vocabulary In general, a language model that has a high lexical diversity ratio is better at capturing the context and meaning of a language. This is because a model that has a high ratio of unique words in its vocabulary tends to generate more accurate and relevant language output. 1.2 Evaluation metrics for lexical diversity ratio There are several metrics that can be used to evaluate the performance of a language model in terms of lexical diversity ratio. Some common metrics include: * F1 score: a harmonic mean of precision and recall, often used in machine translation and information retrieval. * F2 score: a balanced F1 score that takes into account both precision and recall. * F3 score: a harmonic mean of precision and recall, sometimes called the F measure, and is a more widely used metric than F1 and F2. * F1 score with a threshold of 0.5: a higher score indicates better performance. These metrics can be used in combination to get a more complete picture of a language modelâââ‰â¢s performance. 1.3 Use cases for lexical diversity ratio There are several use cases for the lexical diversity ratio, including: * Evaluation of machine translation quality: a low ratio can indicate that the model is not doing a good job of translating the text. * Selection of the best candidates for a recommendation system: a high ratio can indicate that the model is overfitting to the training data. * Quality control in information retrieval systems: a low ratio can indicate that the model is not doing a good job of identifying relevant documents. * Comparison of language models: a high ratio can indicate that the model is not doing a good job of capturing the meaning and context of a language. In summary, the lexical diversity ratio is an important consideration in evaluating the performance of a language model. It measures the ratio of unique words in the vocabulary and is an important metric for evaluating the quality of the language modelâââ‰â¢s output. In the context of a recommendation system, a low ratio can indicate that the model is not performing well, and a high ratio can indicate that the model is overfitting to the training data.'''In [22]:
analyze_text(StableLM) Number of words: 688
Lexical diversity: 0.27
Readability Score 27 -> very_confusingThis model offers a long text with a moderate lexical diversity of 0.27 and quite low readability score at 27.
MosaicML MPT-7B-Chat
This model features the MPT-7B-Chat model, which is fine-tuned using roughly 171,000 conversation samples from one dataset and an additional 217,000 samples from another dataset. Due to its operation on a smaller, shared GPU, responses may take a few seconds. To expedite the process, you can download the model from HuggingFace and run it on your local GPU. Alternatively, you can duplicate the space to bypass the queue and operate in a private environment.
Try it on Hugging Face: https://huggingface.co/spaces/mosaicml/mpt-7b-chat
In [23]:
MosaicLM = '''Lexical Diversity Ratio: What It Is and Why It Matters for Better Communication The concept of âââ¬Ã
“lexical diversityâââ¬Ã refers to the use of words from different linguistic or cultural backgrounds in communication. The term is often used in the context of language policy, where it is seen as an important tool for promoting multilingualism and cultural understanding. However, there is another aspect of lexical diversity that is equally important - its impact on effective communication. In this article, weâââ‰â¢ll explore what the lexical diversity ratio is, why it matters, and how you can improve your own communication skills through greater exposure to diverse vocabulary. What is Lexical Diversity? At its core, lexical diversity means using words that come from different languages, dialects, or cultures when communicating with others. This practice helps to promote understanding between people who speak different languages or have different cultural backgrounds. By exposing ourselves to new words and phrases, we can expand our knowledge base and become more fluent in the language(s) we use every day. Why Does Lexical Diversity Matter? One of the most significant benefits of lexical diversity is that it improves communication effectiveness. When we use a wider range of words, we convey more complex ideas and nuances in our message. This makes our communication more engaging and easier to understand. Additionally, using unfamiliar words can add a touch of elegance and sophistication to our writing or speech. Another reason why lexical diversity is so important is that it promotes inclusivity. By using words from different linguistic or cultural backgrounds, we acknowledge and celebrate the diversity of our society. This can help to break down barriers and create a more inclusive environment where everyone feels valued and respected. How Can We Improve Our Own Lexical Diversity? There are several ways we can increase our exposure to diverse vocabulary. One way is to read books or articles written in different languages or by authors from different cultural backgrounds. Another way is to listen to music or watch movies that feature lyrics or dialogue in different languages. Finally, we can also seek out opportunities to communicate with people from different linguistic or cultural backgrounds, whether itâââ‰â¢s through social media, travel, or volunteering. In conclusion, while lexical diversity may seem like a small part of communication, it has a significant impact on both our ability to effectively communicate and our ability to appreciate the diversity of our world. By increasing our exposure to diverse vocabulary, we can become better communicators, build stronger relationships, and contribute to a more inclusive and equitable society. So next time youâââ‰â¢re looking for inspiration for your writing or speaking, consider exploring new sources of lexical diversity!'''In [24]:
analyze_text(MosaicLM) Number of words: 503
Lexical diversity: 0.48
Readability Score 33 -> difficultMosaicLM generated a fairly long text with the second-highest lexical diversity of 0.48. The readability score is on par with GPT-3.5 Turbo at 33.
Visualisation
Plotly scatterplot is used for visualisation of the results where x = Lexical diversity , y = Readability Score, and the size is set to the Number of words generated by each model, meaning the bigger size of the point, the higher quantity of words the model generated.
In [31]:
data = {
"Model": ["Cohere", "GPT-3.5", "GPT-3.5 Turbo", "GPT-4", "Google Bard", "Hugging Chat", "StableLM", "MosaicLM"],
"Number of words": [172, 358, 382, 724, 437, 476, 688, 503],
"Lexical diversity": [0.44, 0.23, 0.39, 0.44, 0.29, 0.83, 0.27, 0.48],
"Readability Score": [40, 46, 33, 23, 60, 1, 27, 33]
}
df = pd.DataFrame(data)
fig = go.Figure()
for model in df["Model"].unique():
fig.add_trace(go.Scatter(x=df[df["Model"] == model]["Lexical diversity"],
y=df[df["Model"] == model]["Readability Score"],
mode='markers',
marker=dict(size=df[df["Model"] == model]["Number of words"] / 10,
sizemode='diameter'),
text=df[df["Model"] == model]["Model"], name=model))
fig.update_layout(
title="Visualisation of the results of Comparative Study of the Most Popular AI / LLM Models",
xaxis_title="Lexical Diversity",
yaxis_title="Readability Score",
legend_title="Models",
legend=dict( x=.8, y=.95, traceorder="normal",font=dict(family="sans-serif", size=14,color="black"),
bgcolor='rgb(255, 255, 255)', bordercolor="Black", borderwidth=.5 ))
fig.show()
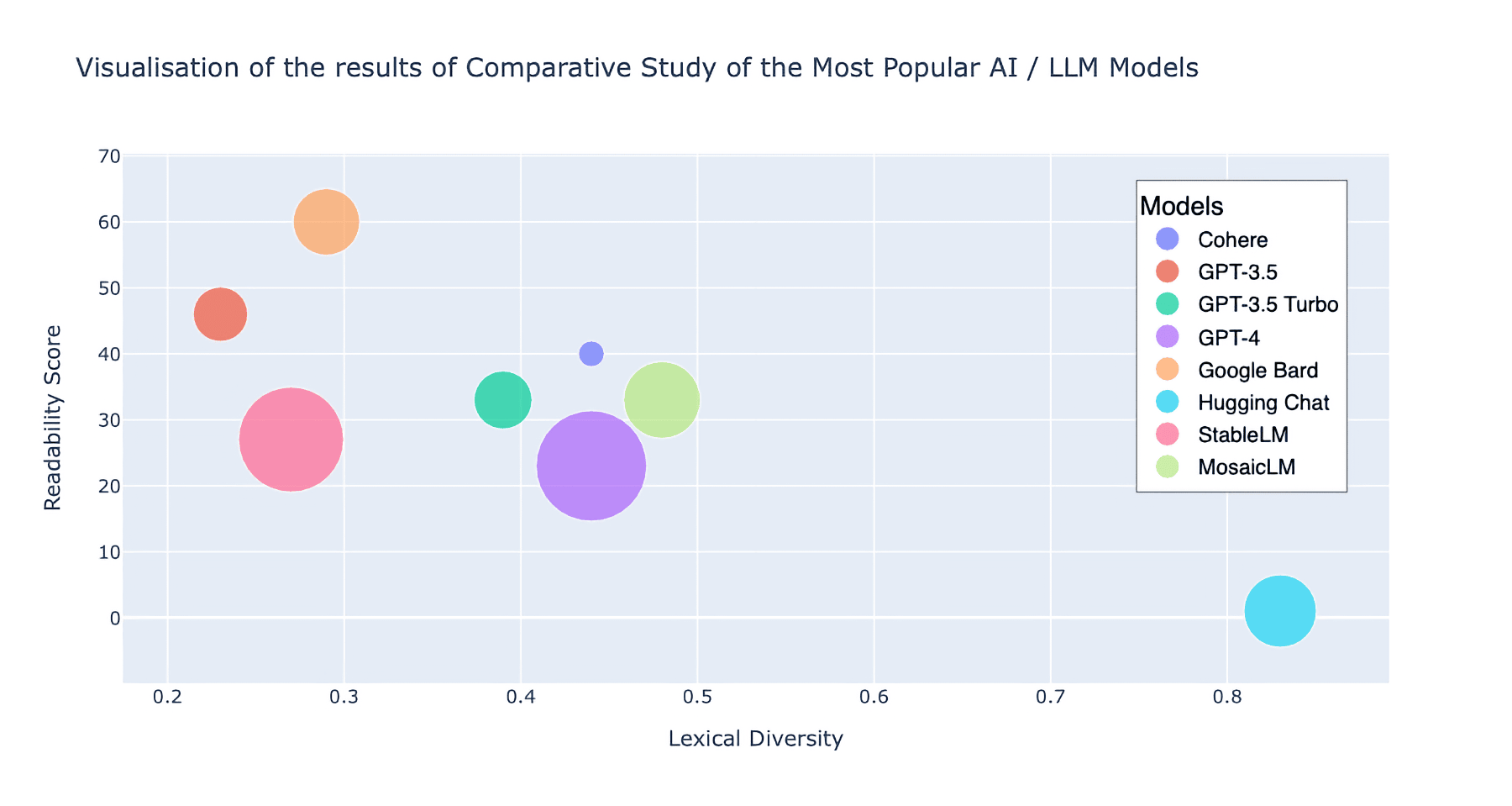
Conclusion
Overall, Google Bard offers the best balance between text length, lexical diversity, and readability with a score of 60. Hugging Chat excels in lexical diversity with a score of 0.83, but lacks readability. GPT-4 and StableLM generate long texts without compromising too much on lexical diversity but suffer from low readability scores.
More observations:
Upon examining the visualization of the data, we can see that there is a negative correlation between the Readability Score and Lexical Diversity. This implies that as the level of Lexical Diversity increases, the Readability Score tends to decrease. In other words, a text containing a higher variety of unique words (greater Lexical Diversity) may be more challenging to comprehend and, as a result, receive a lower Readability Score.
It is also essential to highlight the four models at the core of the graph that exemplify the ideal harmony between Lexical Diversity and Readability. Lexical Diversity engages readers, while Readability enhances content accessibility and user-friendliness. These models include Cohere, GPT-4, MosaicLM, and GPT-3.5 Turbo. Cohere excels in generating concise texts, GPT-4 and MosaicLM are ideal for creating longer, engaging, and easy-to-read content, and GPT-3.5 Turbo strikes a balance between the two.
Limitations
Timeliness: Given the fast-paced advancements in the AI field, this study, completed on May 14, 2023, risks becoming outdated within a few months. As a result, further updates may be necessary to maintain its relevance.
Language: This study solely focuses on prompts and outputs in the English language, thereby limiting the applicability of the findings across different linguistic contexts.
Configuration: To ensure a straightforward comparison, standard default configurations were employed for each model, without any alterations to their settings.
Quantity of Prompts: The study's methodology relies on a single prompt, potentially limiting the comprehensiveness of the findings. A more robust approach would involve increasing the number of prompts and evaluating the average performance metrics across all tested models.
Prompt Content: Performance outcomes may vary across models when the prompt is focused on a different subject or when the level of specificity is adjusted. This study does not account for such variations.
Model Scope: By concentrating on the eight most prevalent language models, this study may overlook other pertinent AI models. Future research endeavors should strive to incorporate a broader array of models for a more extensive evaluation.
Metrics: The study opts to use only three performance metrics-Lexical Diversity, Readability, and Context Length-out of a wide range of available quantitative measures.
Qualitative Analysis: This study does not explore subjective assessment factors such as text structure, topic relevance, and other qualitative aspects of the generated outputs. A more comprehensive evaluation should consider incorporating these additional parameters to strengthen the comparative analysis.
Author Details:
Vasyl Rakivnenko, MBA
IngestAI Labs, Inc.
Email: [email protected]
Date: May 14, 2023

