Word embeddings are a sophisticated method of representing and transforming textual information into a format that machines can comprehend, analyze, and use with ease. Essentially, word embeddings are vector representations of words, and this representation is capable of capturing numerous parameters, such as the context of individual words, semantic relationships, syntactic hierarchy, and even the subtle nuances of languages.
A traditional method for dealing with words programmatically might consist of encoding each word as an individual ID. This method, however, doesn't provide any context, meaning, or association between different words. Enter word embeddings, a technique where words are encoded as dense vectors in a high-dimensional space, with the distance and direction between words representing the relationships between them. This approach facilitates machine learning algorithms to discern context and semantics, thereby delivering significantly more accurate results and predictions.
If words are the atoms of human language, word embeddings are the bridges that anchor them in machine language, enabling you to create your own AI chatbot with enhanced comprehension capabilities.
So, why are embeddings used for text processing? The key reasons are as follows:
Capturing Semantics: Word embeddings position words with similar meanings close to one another in the vector space, indicating their semantic similarity.
Solving the Curse of Dimensionality: Traditional approaches, such as one-hot encoding, often result in highly dimensional data which can impact model performance. Word embeddings effectively counter high-dimensionality by representing words in a lower-dimensional space.
Enhancing Model Performance: By capturing richer semantic meanings and relationships between words, word embeddings often lead to improvements in the performance of machine learning models in various NLP tasks, from text classification and sentiment analysis to language translation and more.
In summarizing, word embeddings deliver a method for translating the humans' rich linguistic intricacies to a machine-understandable format. They are the torchbearers for taking text processing to the next level, making them an indispensable tool in the evolving landscape of Natural Language Processing.
Basics of Word Embeddings
Understanding the theoretical framework behind word embeddings
Diving deep into the theoretical underpinnings, word embeddings are grounded in the idea of vector space models (VSMs). VSMs provide a bridge between human language perception and machine language by representing words in multi-dimensional space, in some thousands of dimensions. High dimensional spaces aid in capturing linguistic patterns and contextual semantics of words.
Each dimension in this space corresponds to a semantic feature that distinguishes one word from another. For instance, one dimension could distinguish verbs from nouns, another could signify past and present tense, and yet another could distinguish between singular and plural forms. The location of each word in this space is learned from text data and optimized to position similar words closer together in space and dissimilar words farther apart.
Importance and benefits of word embeddings in NLP
Word embeddings are more than just a core component of NLP. They unlock a myriad of breakthroughs in the field:
Semantic and Syntactic Awareness: Word embeddings lead to semantic relationships between words. Words used in similar contexts are mapped close in the vector space. Similarly, words that are syntactically similar tend to be closer.
Dimensionality Reduction: While traditional methods of language representation like Bag of Words (BoW) and TF-IDF create high-dimensional sparse matrices, word embeddings help in reducing dimensionality, creating dense vector representations for each word.
Improved Model Performance: Incorporating word embeddings generally enhances the performance of NLP tasks like text classification, sentiment analysis, and machine translation.
Differentiating word embeddings from traditional methods
Traditional methods, such as BoW, create a large sparse matrix where each word is represented as a one-hot-encoded vector of size equal to the size of the vocabulary. However, such methods fail to capture the syntactic and semantic relationships between words.
In contrast, word embeddings provide dense vector representations where each dimension can represent some latent syntactic or semantic feature. Embeddings further capture the spatial relationships between words, meaning that words with similar usage are placed closer to each other in the embeddings space.
In essence, word embeddings overcome many limitations of traditional language representation methods by effectively capturing semantic nuances, providing dimensional efficiency, and boosting the performance of downstream tasks in NLP.
Word Embedding Models
As the pursuit of rendering machines capable of understanding human language advances, a multitude of models have been introduced to generate word embeddings. These models are truly instrumental in converting words into a format that provides insights into their contextual and syntactic usage facilitating tasks as varied as AI-powered search to text classification.
Bag of Words (BoW)
The Bag of Words (BoW) model, one of the most basic forms to transform text data into numerical vectors, perceives each document as an unordered collection or 'bag' of words. It represents each document as a vector in an m-dimensional space where 'm' pertains to the number unique words throughout all documents - or corpus. Each dimension tallies up how many times a particular word appears within individual documents but disregards context and grammar. BoW, in its essence, provides a simple way to represent textual data, however, when it comes to extracting deeper relationships between words and creating knowledge graphs and LMs, it falls short.
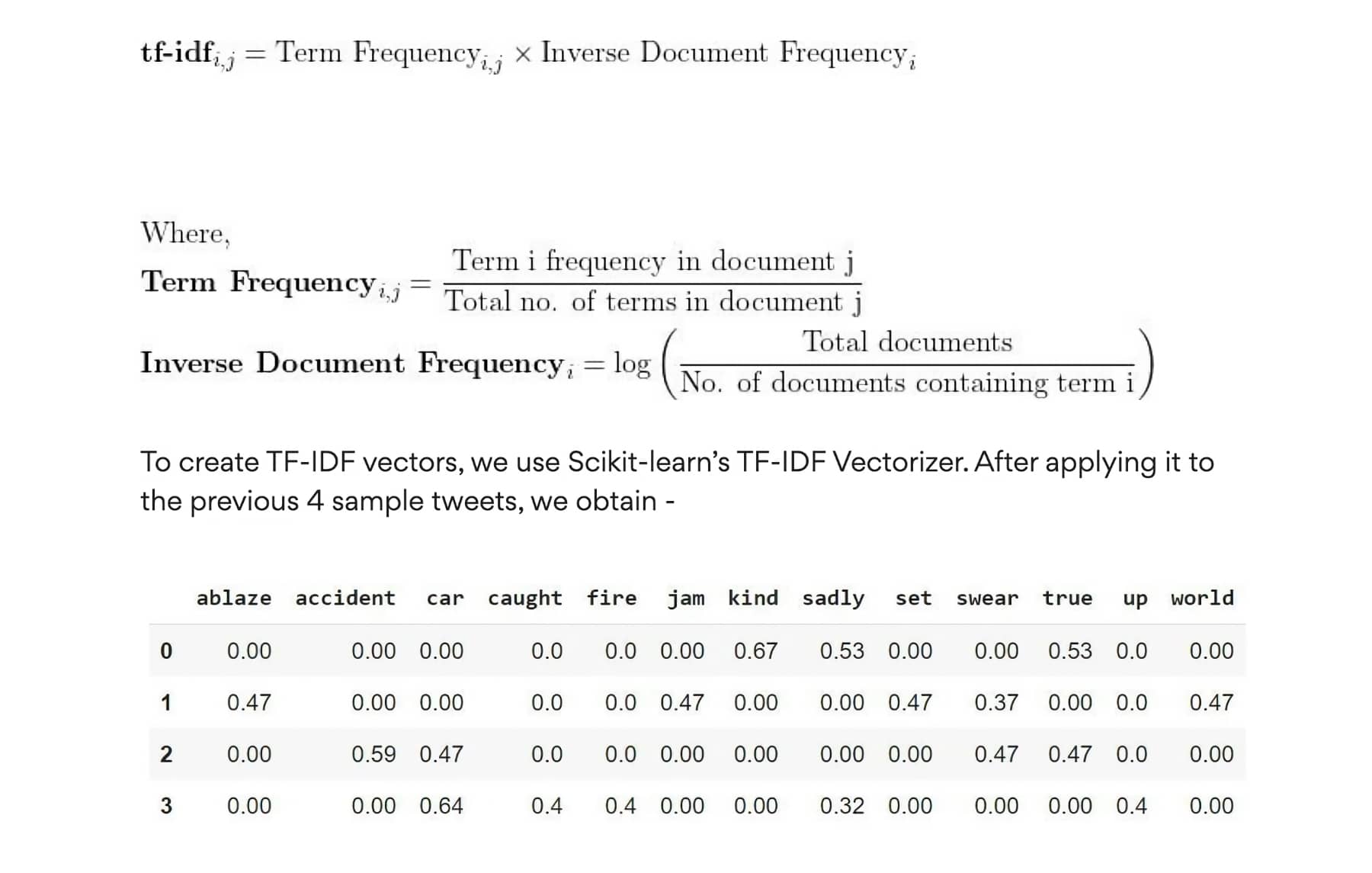
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF is another traditional text processing algorithm that refines BoW by calculating the frequency distribution of every term for each document while also considering how commonly those terms appear across all documents. This approach helps diminish importance given to common words while elevating attention on more pertinent keywords specific to individual texts.
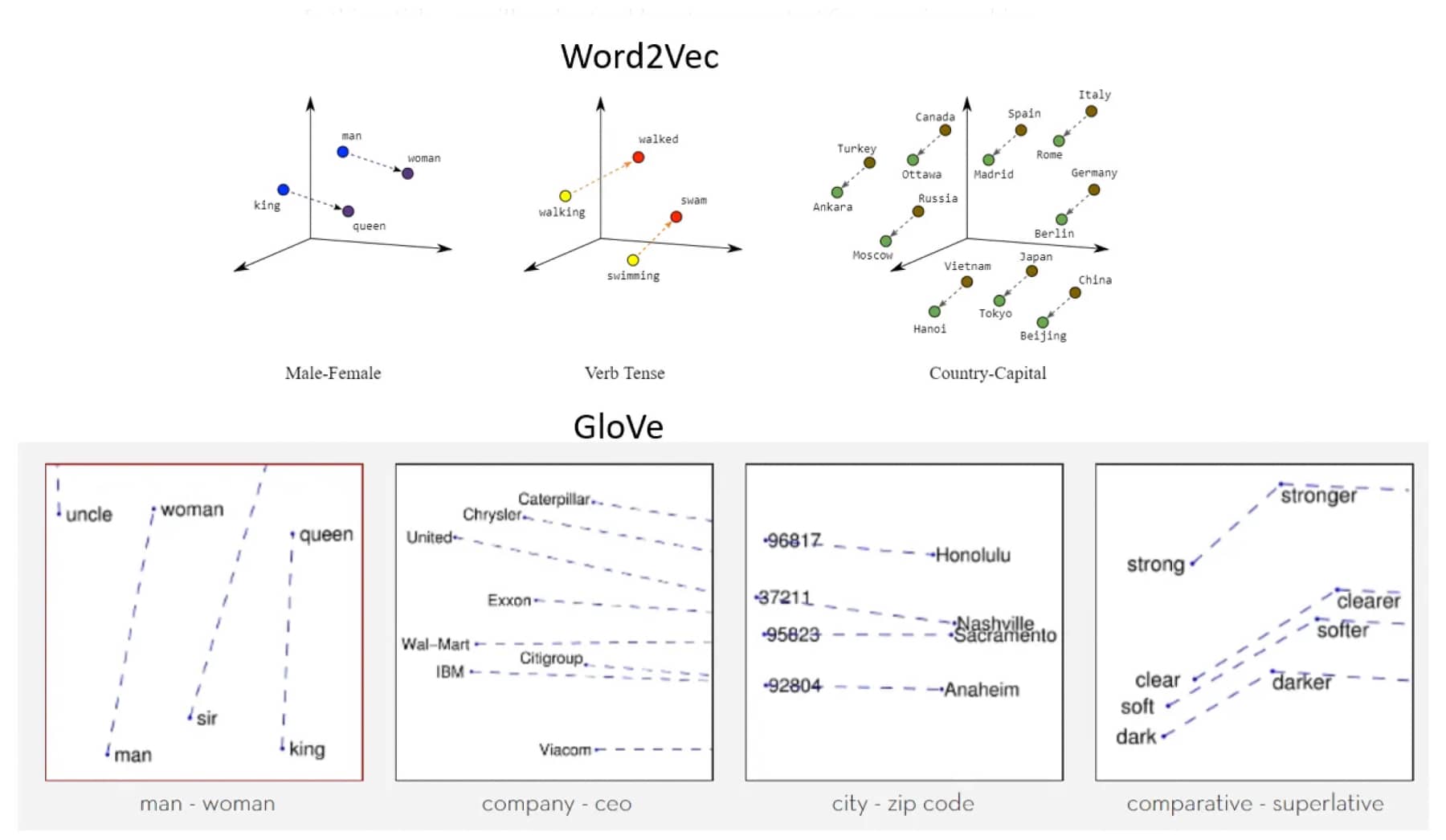
Word2Vec
Word2Vec constitutes a pivotal breakthrough which takes our capability beyond just counting occurrences towards understanding contexts and semantic connections between words. Leveraging neural networks, it situates semantically similar words closer together within its defined vector space based on their relative meanings - making it possible for us discern not only what each word means but also how they relate with one another.
GloVe (Global Vectors for Word Representation)
Emerging from Stanford's labs is GloVe, an unsupervised learning algorithm designed specifically for capturing global statistic information from large corpora then embedding them directly into vectors â⬔ hence combining strengths derived from both BoW/TF-IDF and predictive methods like Word2Vec into one powerful technique acknowledged for its expressiveness versus computational cost trade-off advantages.
FastText
Then we have FastText developed by Facebook AI Research Lab which extends upon original concepts presented by Word2vec yet adds further granularity by delving down below word-levels â⬔ blending semantic nuances inherent in subword-level information captured through char-based n-grams with power derived from skip-gram architectures thereby enabling enhanced ability when dealing with morphologically rich languages or otherwise seldom-seen words.
While conventional language representation approaches may suffice under simplistic requirements, when faced with complex NL tasks demanding deeper understanding such as sentiment analysis or machine translation endeavors â⬔ leveraging these novel NLP methodologies becomes notably advantageous due largely relative strides achieved regarding contextual comprehension spanning semantics through syntax alike.
BERT (Bidirectional Encoder Representations from Transformers)
BERT, standing for Bidirectional Encoder Representations from Transformers, represents one of the most recent and advanced word embedding methods. Developed by Google, it uses a transformer, an attention mechanism that learns contextual relations between words in a text.
What sets BERT apart is its bidirectional training of transformers. In previous models like Word2Vec or GloVe, encoders look at text data independently either from left to right (forward direction) or right to left (backward direction). On the other hand, BERT's model reads the entire sequence of words at once; hence it is bidirectionally trained. This allows each wordââ¬â¢s representation to be informed by both its preceding and following context.
Consequently, BERT has been instrumental in improving machine understanding of languages by considering multiple interpretations of a single word based on its surrounding context â⬓ a significant leap on many NLP tasks such as question-answering or sentiment analysis tasks.
Integrating Transformers into models like BERT demonstrates how diversification within word embeddings methodologies continues to advance our ability to process natural language data effectively.
Word Embedding Model | Description |
|---|---|
Bag of Words (BoW) | Simplistic model representing frequency of words, disregards grammar or word placement |
TF-IDF (Term Frequency-Inverse Document Frequency) | Gives importance to rarity of words, fails to capture semantic and syntactic context |
Word2Vec | Uses neural networks, positions similar context words near each other in vector space |
GloVe (Global Vectors for Word Representation) | Balances BoW/TF-IDF and Word2Vec benefits by capturing global statistics and local semantics |
FastText | Views each word as a ââ¬Åbag-of-character-n-gramsââ¬Â, considering morphological information |
BERT (Bidirectional Encoder Representations from Transformers) | Learns contextual relations between words through bidirectional training |
In-depth Understanding of Word2Vec
The Word2Vec methodology represents a leap forward in the field of NLP. Unlike its predecessors, Word2Vec utilizes neural networks to analyze words in a multi-dimensional space. It encapsulates word associations, semantic nuances, and syntactical cues, offering a much more robust understanding of a given text corpus. Word2Vec model, often cited as the go-to model, has a unique approach that merits closer scrutiny - one that helps overcome some typical limitations of ChatGPT. The unique approach of Word2Vec makes it one of the best ChatGPT alternatives in tasks where the context of input text is crucial.
The Unique Approach of Word2Vec
Word2Vec's innovation lies in its ability to plot words based on context rather than pure frequency. It eschews the concept of 'a bag of words' and instead maps words based on their relationship with surrounding words. This approach affords the model a more nuanced understanding of syntax and semantics.
In its multi-dimensional vector space, words with similar usage and connotations are positioned near each other. This placement means that, for example, 'kitten' would be closer to 'cat' than 'house'. These vector spaces can consequently encapsulate a significant amount of syntactic and semantic information about a word.
Explanation of Two Architectures: Continuous Bag of Words (CBOW) & Skip-gram
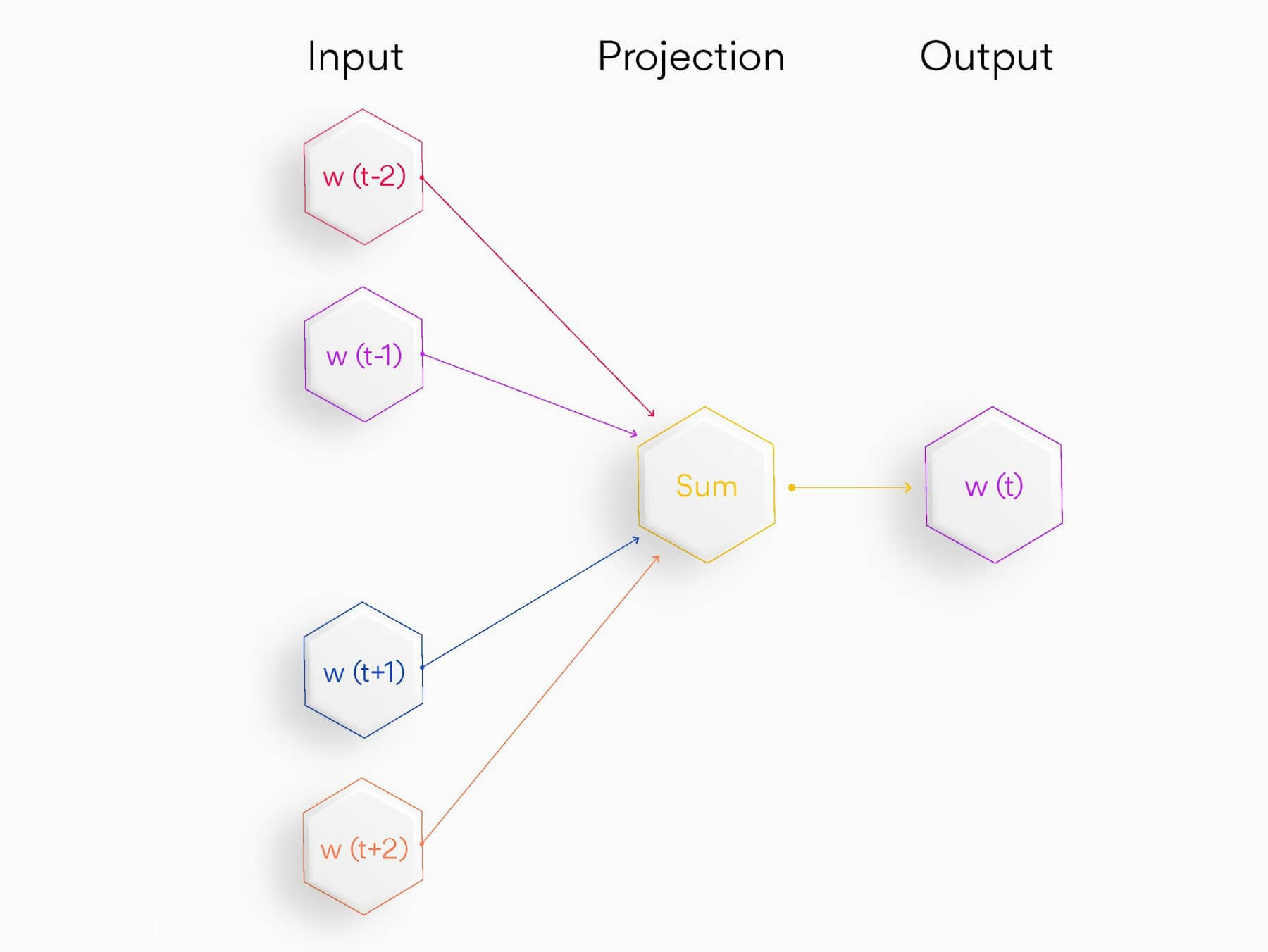
There are two main learning models or architectures within Word2Vec: Continuous Bag of Words (CBOW) and Skip-gram.
Continuous Bag of Words (CBOW): In the CBOW model, the neural network predicts the current word based on the context, which includes surrounding words. CBOW's focus on understanding and predicting the context makes it faster and more accurate when dealing with frequent words.
Skip-gram: The Skip-gram model reverses the CBOW model. Rather than predicting a word based on its context, it uses the current word to predict the surrounding words. This model is exceptional at understanding rare words or phrases in the corpus because it provides more weight to lesser-used terms.
It's worth noting that both CBOW and Skip-gram are complementary in the sense that both models learn different types of word semantics depending on the dataset, and it might be beneficial to combine these models for certain applications.
The Role of Word Embedding in NLP
Word embeddings have revolutionized Natural Language Processing (NLP) by enabling machines to understand human language in a nuanced context. Let's examine their roles a bit more.
Understanding the Semantic and Syntactic Roles of Word Embeddings
Word embeddings capture more than just word frequencies, making them important even in areas like AI personal knowledge management. They encapsulate semantic and syntactic relationships, distinguishing word meanings based on context and neighboring words.
Semantic relationships refer to the meanings that words carry. By storing words in vector space, word embeddings allow semantically similar words to be mapped together. This feature has been particularly useful in tasks like sentiment analysis or language translation where understanding meaning is critical.
Syntactic relationships pertain to the grammatical structure and order of words in a sentence. Word embeddings capture these relationships by observing sentence patterns over a large corpus of text, giving linguistic insights regarding tense, count, and gender.
Handling Unseen Words: An Advancement Over Older Techniques
One problem that frequently hampers NLP processes is the handling of unseen or out-of-vocabulary (OOV) words. Older techniques like One-Hot encoding or BoW fail to provide a solution to this problem.
Word embeddings, equipped with context capturing capabilities, bring about advancement in handling unseen words. For instance, FastText, an enhanced version of Word2Vec, generates embeddings for OOV words by summing up embeddings of its constituent character n-grams. While not perfect, it offers a pragmatic stride toward solving the unseen words problem, underlining the importance of word embeddings in advancing the frontiers of NLP.
Conclusion
In the realm of Natural Language Processing (NLP), word embeddings are akin to powerful catalysts, transforming the way machines understand and interpret human language. By representing words as dense vectors in a high-dimensional space, word embeddings encapsulate the nuanced semantic and syntactic relations between words, surpassing the limitations of traditional methods like Bag of Words (BoW) and TF-IDF.
From elucidating the theoretical underpinnings of word embeddings to examining various word embedding models like BoW, TF-IDF, Word2Vec, GloVe, and FastText, we have embarked on a comprehensive journey exploring this fascinating domain. We've also delved into the unique Word2Vec model, distinguishing its two architectural paradigms, Continuous Bag of Words (CBOW), and Skip-gram.
The value of word embeddings is underscored by their crucial roles in NLP, in capturing semantic and syntactic roles, and offering ways to handle unseen words. These advancements underscore how instrumental word embeddings are for progressing NLP.
Looking ahead, we can envision even more advances in the realm of word embeddings. As we pursue deeper understandings of language and strive for more effective ways of mirroring the complexities and dimensions of human language in the digital space, word embeddings will undoubtedly continue to be at the forefront of this exhilarating journey in NLP. The world of NLP, particularly artificial intelligence in knowledge management, continues to evolve, and word embeddings are certain to be a crucial part of this fascinating journey.

