
Retrieval Augmented Generation (RAG) is a technique in natural language processing that aims to improve the accuracy and reliability of responses from large language models (LLMs) like GPT-3.
To better comprehend the concept of Retrieval-Augmented Generation (RAG), it's beneficial to understand the basics of word embedding in NLP.
RAG works by retrieving relevant information from an external knowledge base to provide additional factual context to the LLM. This helps ground the LLM on accurate, up-to-date information instead of relying solely on its training data.
Some key benefits of RAG:
Provides factual, specific responses instead of inconsistent, random facts
Allows LLMs to incorporate domain-specific information
Enables generative responses grounded in recent, verifiable data
Can reduce hallucination and improve overall quality of LLM outputs
Challenges of using LLMs alone
Large language models (LLMs) like GPT-3 and BERT have shown impressive capabilities in generating human-like text. However, when used alone, LLMs also face some key challenges:
LLMs can be inconsistent and regurgitate random facts
LLMs are trained on vast amounts of text data scraped from the internet
This training process is statistical - LLMs learn patterns but not meaning
As a result, LLMs may generate responses that are:
Inconsistent across questions
Contain random, irrelevant facts from training data
Lack a coherent underlying meaning
LLMs lack up-to-date real world information
Most LLMs are static after initial training
They lack knowledge of current events and facts
LLMs may generate plausible-sounding but incorrect responses about recent news or data
LLMs lack domain-specific information
LLMs are generally trained on open-domain data
They lack access to proprietary organizational data
Struggle to respond accurately to domain-specific questions
Consequences
Hallucination - generating confident but incorrect responses
Factual inaccuracy
Irrelevant responses
Inability to handle context-dependent queries
Lower quality outputs
This presents challenges in building production AI systems using LLMs. Relying solely on LLMs results in outputs that:
Cannot be fully trusted
Lack specificity and grounding in facts
Fail to adapt as circumstances change
Summary of LLM limitations:
LLM Limitation | Description | Consequence |
|---|---|---|
Inconsistency | Statistical learning leads to irregular outputs | Lower quality, less reliable |
Information staleness | Static after training, no knowledge of recent events | Factually inaccurate |
Lack of domain knowledge | Trained on open-domain data only | Struggles with domain-specific queries |
To address these limitations, we need solutions that provide LLMs with up-to-date, contextual information. This is where Retrieval Augmented Generation comes in.
While RAG models have their strengths, there are also alternatives to ChatGPT that are worth considering.
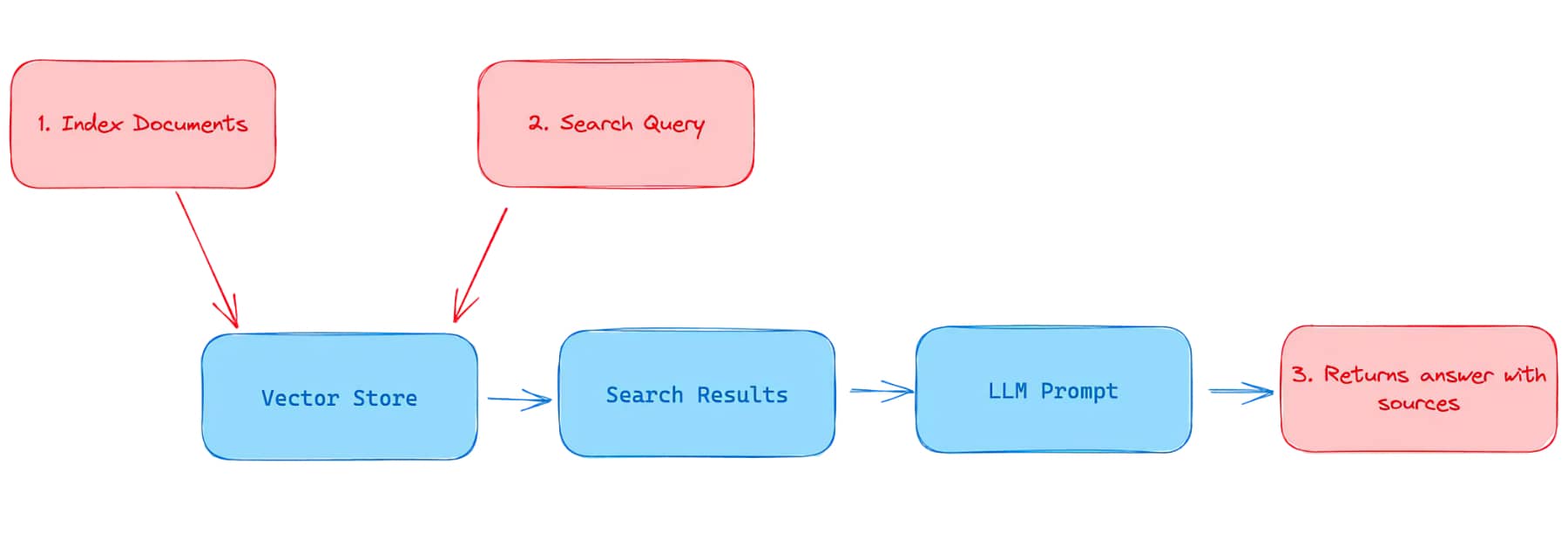
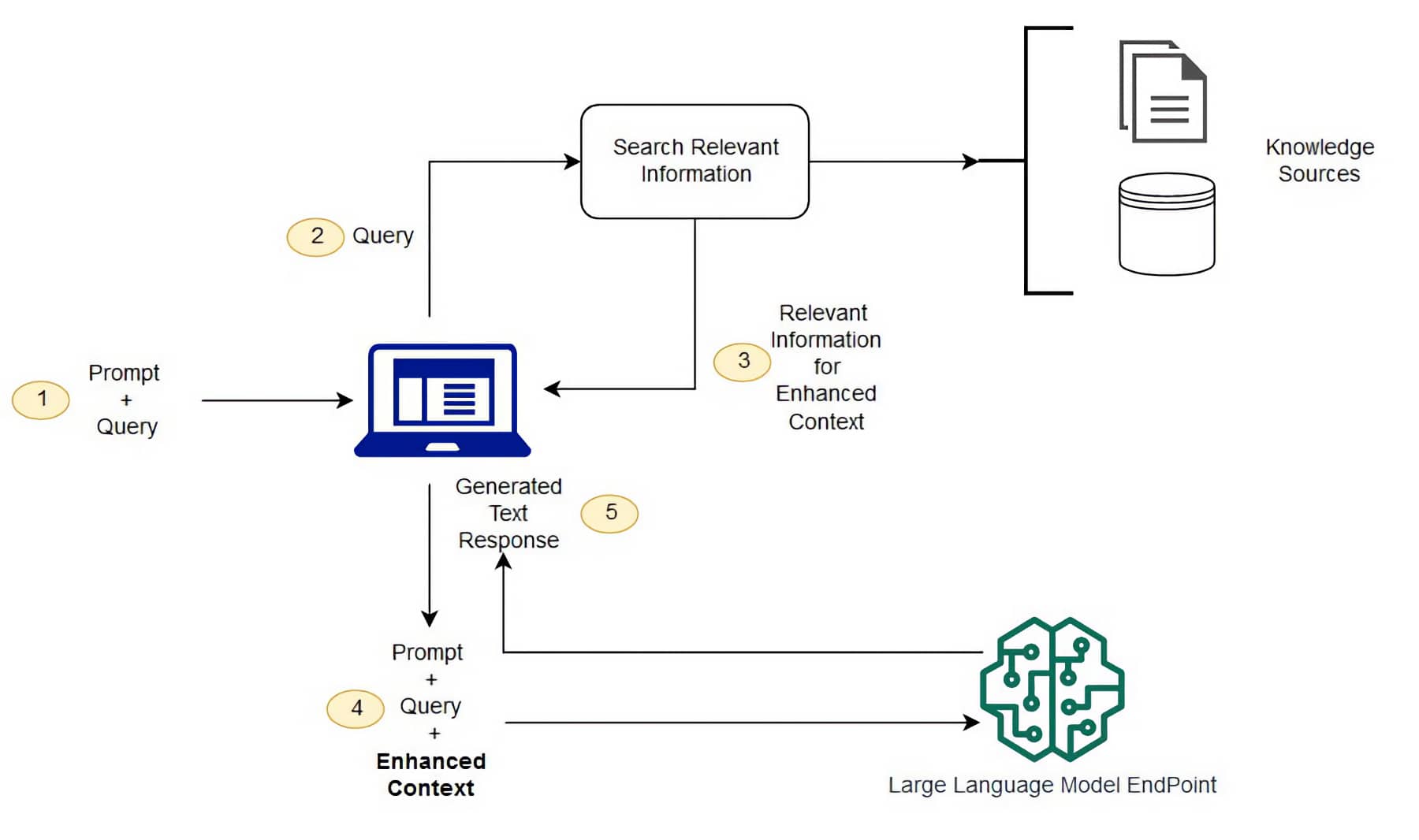
How Retrieval Augmented Generation (RAG) works
Retrieval Augmented Generation (RAG) is a technique that combines large language models (LLMs) with a retrieval mechanism to provide contextual information.
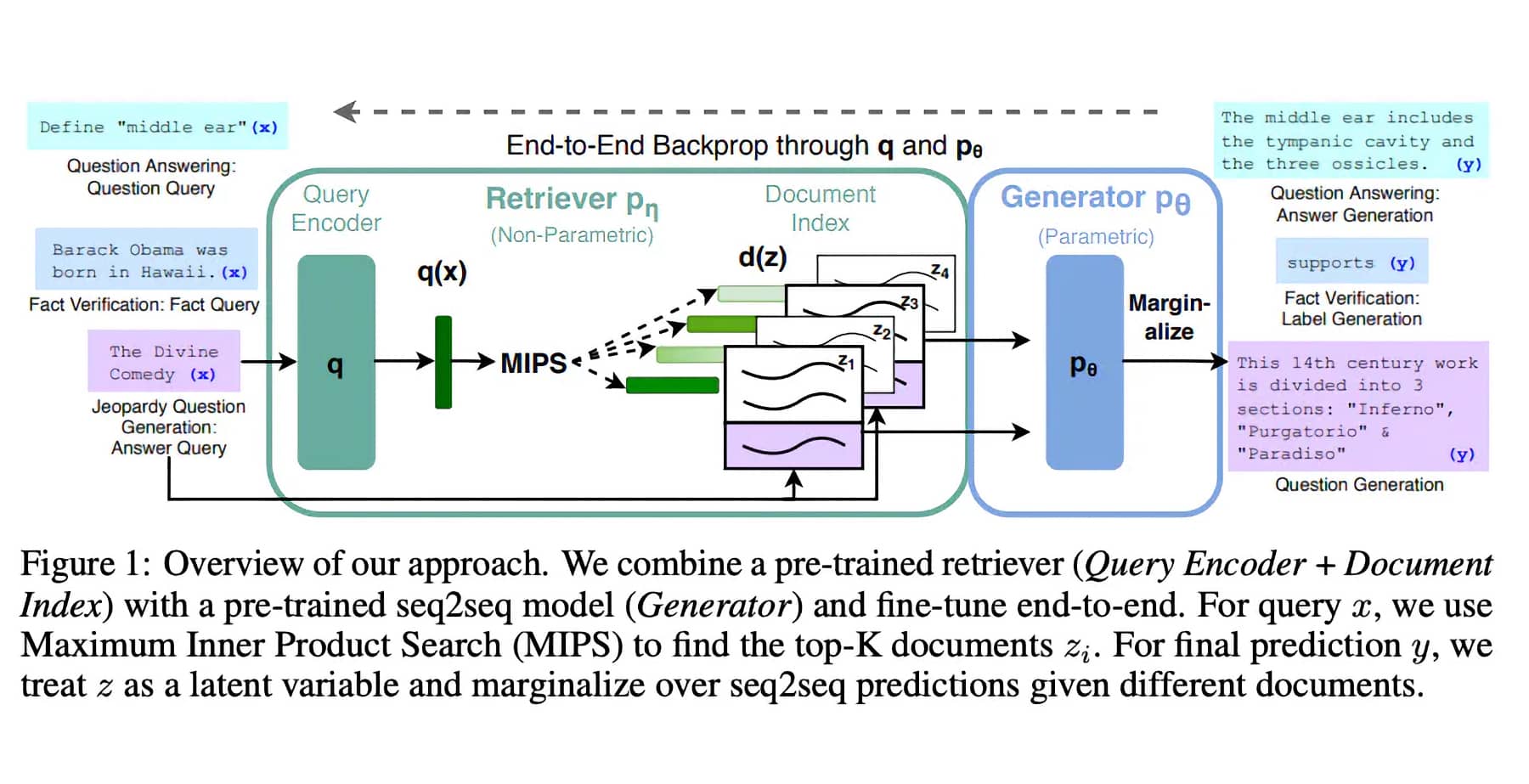
Retrieval-Augmented Generation (RAG) operates through a unique two-step process that sets it apart from traditional language models. This process involves both the retrieval of relevant documents and the generation of responses based on these documents.
In the first step, the RAG model receives an input, such as a question or a prompt. It then uses a retrieval system to search through a vast database of documents to find the ones that are most relevant to the input. This retrieval system is powered by a dense vector retrieval method, which allows the model to efficiently sift through the database and pinpoint the most pertinent documents.
Once the relevant documents have been retrieved, the RAG model moves on to the second step: response generation. Here, the model uses a sequence-to-sequence transformer to generate a response. This transformer takes into account both the original input and the retrieved documents, ensuring that the generated response is not only accurate but also contextually relevant.
The beauty of the RAG model lies in its ability to combine the strengths of retrieval-based and generative models. By retrieving relevant documents before generating a response, the RAG model can provide more accurate and contextually appropriate responses than traditional language models. This makes RAG models particularly useful for tasks such as question answering and dialogue systems.
The overall workflow is:
Retrieve relevant facts, documents, or passages using a retrieval model
Provide the retrieved information as additional context to the LLM
LLM generates an informed, grounded response
Retrieval Models
RAG relies on efficient retrieval models to find relevant information from a knowledge source given a query:
BM25: Probabilistic retrieval model based on term frequency and inverse document frequency
TF-IDF: Weights terms based on rarity across corpus
Neural network embeddings: Maps text to vector representations and finds semantically similar passages
Providing Retrieved Context
The top retrieved results are concatenated into a context document
This context document is provided to the LLM along with the original query
The LLM leverages the retrieved information to inform its response
LLM Generation
With relevant context, the LLM can generate responses that are:
Factual and specific
Grounded in the provided information
More accurate and relevant to query
Avoids hallucination and arbitrary responses
Differences from LLM alone
RAG differs from using an LLM alone in a few key ways:
Dynamic - retrieves recent facts instead of relying solely on static training data
Incorporates external knowledge through retrieval mechanism
Provides relevant context to anchor the LLM
Allows tracing outputs to retrievals and improves auditability
RAG offers an efficient way to improve responsiveness and accuracy of LLMs by complementing their capabilities with retrievals.
Benefits of using RAG
Embracing Retrieval-Augmented Generation (RAG) brings a host of advantages that can significantly enhance the performance of AI systems. Here are some key benefits:
1. Enhanced Accuracy: By retrieving relevant documents before generating a response, RAG models can provide more accurate and contextually appropriate responses. This is a significant improvement over traditional language models that generate responses based solely on the input they receive.
2. Scalability: RAG models are designed to work with large databases, making them highly scalable. They use a dense vector retrieval method to efficiently sift through vast amounts of data, ensuring that the size of the database doesn't compromise the model's performance.
3. Versatility: The two-step process used by RAG models makes them versatile and adaptable. They can be used for a wide range of tasks, from question answering and dialogue systems to AI-powered knowledge management and enterprise search systems.
4. Continuous Learning: RAG models are capable of continuous learning. As they interact with more data, they become better at retrieving relevant documents and generating accurate responses. This ability to learn and improve over time makes RAG models a valuable asset in the rapidly evolving field of AI.
5. Autonomy: By enhancing the accuracy and relevance of AI responses, RAG models contribute to the development of autonomous digital enterprises. They improve the efficiency and effectiveness of AI systems, enabling businesses to automate more processes and make more data-driven decisions.
Retrieval Augmented Generation (RAG) provides several key benefits over using large language models (LLMs) alone:
Provides LLMs with up-to-date, factual information
RAG retrieves recent facts and data from updated knowledge sources
Overcomes limitation of LLMs being static after training
Reduces hallucinations and factual inconsistencies
Enables generating responses grounded in the latest information
Enables LLMs to access domain-specific information
RAG allows injecting domain knowledge from proprietary data
LLMs can incorporate organization-specific data unavailable during training
Vastly improves performance on domain-specific queries
Contextual responses aligned with business needs
Generates more factual, specific and diverse responses
Retrieved facts make outputs more specific and factual
Wider range of external knowledge increases diversity
Mitigates generic, inconsistent LLM responses
Evaluation shows RAG improves correctness on benchmarks
Allows LLMs to cite sources and improves auditability
RAG provides the LLM with context documents
Responses can be traced back to original retrievals
Enables explaining outputs and sources to users
Critical for domains like law, finance that require audit trails
More efficient than retraining LLMs with new data
Retraining LLMs is time-consuming and computationally expensive
RAG achieves accuracy gains by simply providing new context
Faster way to incorporate updated knowledge vs. LLM retraining
Saves time and money while boosting performance
Other Benefits
Customizable based on use case - index any knowledge source
Can be implemented incrementally to augment existing systems
Enables hybrid approaches that combine its strengths with LLMs
The integration of RAG models is a significant step towards unifying LLMs and knowledge graphs.
Summary
Benefit | Description |
|---|---|
Up-to-date information | Pulls latest facts dynamically |
Domain knowledge | Incorporates proprietary data |
Improved quality | More accurate, factual and specific |
Auditability | Can trace outputs to sources |
Efficiency | Faster and cheaper than LLM retraining |
RAG provides a flexible, efficient way to boost LLM performance for production systems.

Applications of RAG
Retrieval augmented generation (RAG) has diverse applications across many industries. RAG can enhance large language models (LLMs) in systems for:
Question answering
RAG is highly effective for question answering systems
Retrieval model finds relevant facts or passages with answers
LLM formulates complete answer using retrieved context
Improves accuracy on benchmarks like Natural Questions
RAG models are instrumental in AI powered knowledge management systems, enhancing their ability to retrieve and generate relevant responses.
Content generation
Can aid tasks like summarization, story generation, etc.
Retrievals provide factual details and context
LLM integrates facts into coherent narratives
Outputs are more informative and engaging
Reducing hallucination in LLMs
Hallucination is a key risk when using LLMs
RAG mitigates this by grounding LLM on retrieved info
Constraints LLM responses to provided context
Lowers chances of arbitrary or incorrect responses
Customer service and chatbots
RAG enables chatbots to incorporate customer data
Can retrieve customer history and profile information
Allows providing personalized and contextually relevant replies
Significant benefits for customer service use cases
Domain-specific implementations
Legal: Retrieve relevant case law and precedents
E-commerce: Fetch product specs, inventory, orders
Finance: Incorporate market data, risk models
Healthcare: Use medical ontologies, patient records
Custom index of domain knowledge
Other applications
Structured data retrieval from databases
Real-time event and news tracking
Integrating multimedia information
Incorporating organizational policies
Numerous possibilities based on indexed knowledge
Example Implementations
Industry | Knowledge Source | Use Cases |
|---|---|---|
Legal | Case law, precedents | Litigation support, contract review |
E-commerce | Product catalogs, orders | Customer support, product recommendations |
Finance | Market data, risk models | Investment advice, compliance |
Healthcare | Ontologies, patient records | Diagnosis support, personalized care |
RAG is a flexible technique that can enhance LLMs across many verticals by grounding them in specialized knowledge.
The power of RAG models is evident in their application in AI-powered enterprise search systems.
Conclusion
In summary, Retrieval Augmented Generation (RAG) offers an effective technique to overcome key limitations of large language models (LLMs) and improve the quality and specificity of AI system outputs.
Key strengths of the approach
Combines strengths of performant retrieval models and creative LLMs
Retrieval provides relevant facts and context
LLMs generate fluent, coherent responses
Enables dynamic, up-to-date responses by retrieving recent information
Handles domain-specific use cases by injecting organizational data
Reduces hallucination by grounding LLMs on retrievals
Improves auditability by tracing LLM responses back to sources
More efficient alternative to ongoing LLM retraining
Range of applications
Question answering systems
Chatbots and customer service
Content generation
Reducing hallucination
Domain-specific implementations in legal, healthcare, e-commerce, and more
Future directions
Some promising areas for further development of RAG:
Advanced retrieval models like dense retrievers to improve context
Methods to retrieve structured, multimedia data
Tighter integration between the retriever and LLM components
Hybrid approaches combining RAG strengths with other techniques
Scaling RAG across massive corpora and datasets
It models play a pivotal role in the evolution towards an autonomous digital enterprise.
RAG provides an important tool for building production-ready AI systems that can meet business needs for accuracy, specificity, and relevance. As LLMs continue advancing, RAG offers an efficient method to improve their capabilities and ground them in real-world knowledge.
When it comes to choosing the best AI search engine, the capabilities of RAG models can't be overlooked.
With further innovation in retrieval methods and system integration, RAG is poised to enable the next generation of useful, reliable AI applications across many industries.

