
In the rapidly evolving field of natural language processing (NLP), Retrieval-Augmented Generation (RAG) has emerged as a groundbreaking technique that enhances the capabilities of Large Language Models (LLMs). By seamlessly integrating external knowledge into the generation process, RAG systems have the potential to revolutionize various applications, such as question answering, dialogue agents, and text summarization.
At the core of RAG lies the critical component of knowledge retrieval, which plays a pivotal role in enabling LLMs to access and leverage relevant information from vast external sources. This article delves into the intricacies of knowledge retrieval within RAG systems, exploring its significance, key components, and the cutting-edge techniques that drive its effectiveness.
Through an in-depth examination of indexing optimization, query optimization, and embedding techniques, we will unravel the complexities of knowledge retrieval and shed light on its indispensable role in powering RAG systems. Furthermore, we will discuss the challenges and considerations associated with knowledge retrieval, as well as the future directions and opportunities that lie ahead in this exciting field.
By the end of this article, readers will have a comprehensive understanding of the vital importance of knowledge retrieval in RAG systems and its potential to shape the future of NLP applications.
Key Component | Description |
Indexing | The process of organizing and storing external knowledge in a structured format for efficient retrieval. |
Querying | The act of formulating and expressing information needs to retrieve relevant knowledge from the indexed sources. |
Retrieval | The task of identifying and extracting the most relevant pieces of knowledge based on the given query. |
Table 1: Key components of knowledge retrieval in RAG systems.
In the upcoming sections, we will embark on a journey to explore the fascinating world of knowledge retrieval in RAG systems, unraveling its intricacies and showcasing its immense potential to revolutionize the field of NLP.
Understanding Knowledge Retrieval in RAG
Before delving into the intricacies of knowledge retrieval in RAG systems, it is essential to establish a clear understanding of what knowledge retrieval entails. Knowledge retrieval refers to the process of identifying, extracting, and leveraging relevant information from external sources to enhance the performance and capabilities of LLMs in generating accurate and contextually appropriate outputs.
Definition of Knowledge Retrieval
In the context of RAG, knowledge retrieval involves the following key aspects:
Identifying relevant sources: Determining the appropriate external knowledge sources, such as databases, documents, or web pages, that contain information pertinent to the task at hand.
Extracting relevant information: Employing techniques to accurately locate and extract the most relevant pieces of information from the identified sources.
Integrating retrieved knowledge: Incorporating the retrieved knowledge into the LLM's generation process to improve the quality and accuracy of the generated outputs.
Key Components of Knowledge Retrieval
Knowledge retrieval in RAG systems consists of three fundamental components:
Indexing: Indexing involves organizing and storing the external knowledge in a structured format that facilitates efficient retrieval. It typically includes techniques such as document parsing, tokenization, and the creation of inverted indexes.
Querying: Querying refers to the process of formulating and expressing information needs in a way that enables the retrieval system to identify relevant knowledge from the indexed sources. This involves techniques such as query parsing, expansion, and optimization.
Retrieval: Retrieval is the task of identifying and extracting the most relevant pieces of knowledge based on the given query. It involves applying similarity measures, ranking algorithms, and filtering techniques to determine the best matching knowledge from the indexed sources.
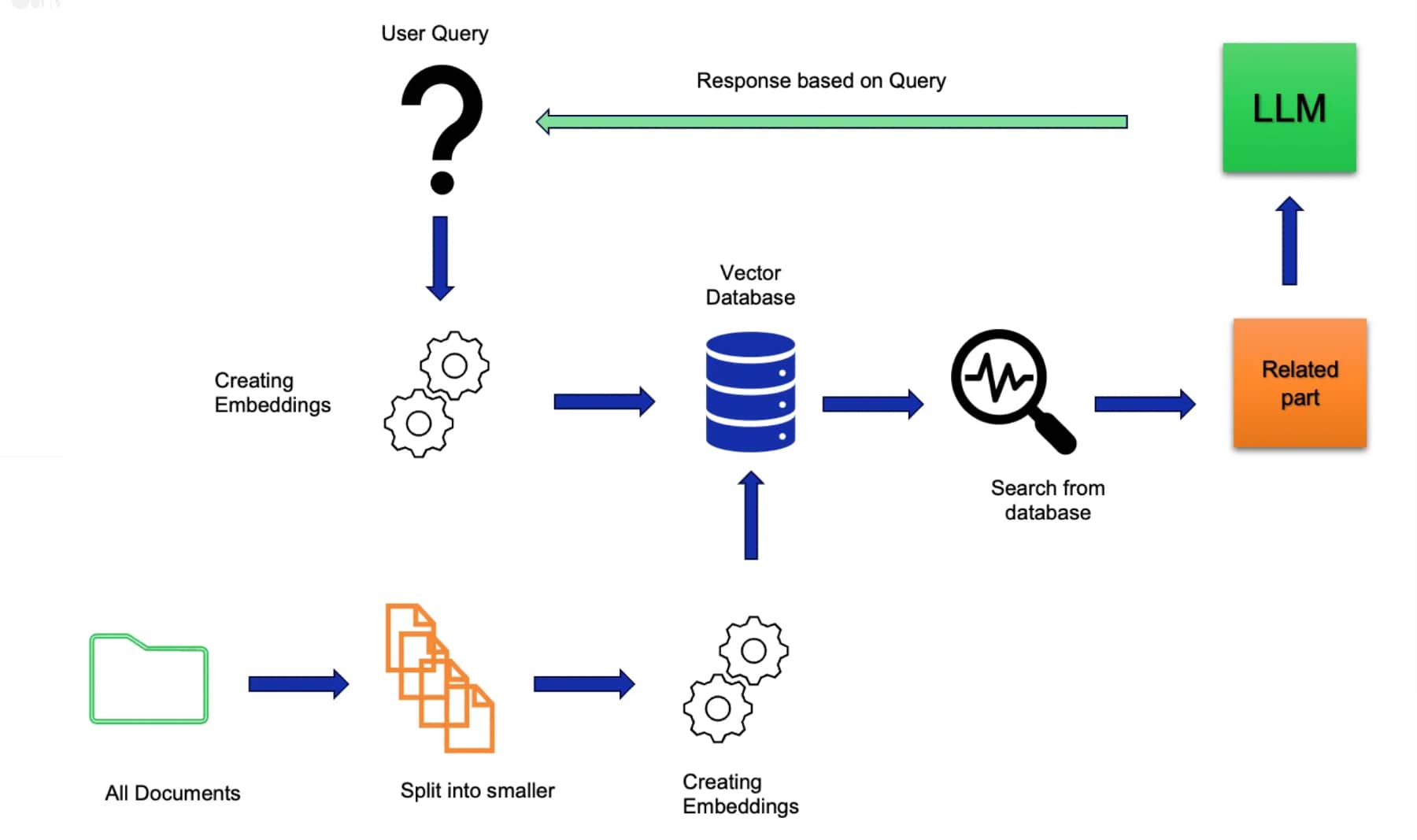
Significance of Knowledge Retrieval in RAG Systems
The significance of knowledge retrieval in RAG systems cannot be overstated. It plays a crucial role in several aspects:
Enhancing LLM's knowledge base: By retrieving relevant external knowledge, RAG systems can significantly expand the knowledge base of LLMs, enabling them to generate more accurate and informative outputs.
Improving context understanding: Knowledge retrieval allows RAG systems to better understand the context of a given query or prompt by providing additional relevant information, leading to more contextually appropriate responses.
Mitigating knowledge gaps: RAG systems can retrieve up-to-date and domain-specific knowledge, helping to mitigate the knowledge gaps that may exist in the pre-training data of LLMs.
Enabling knowledge-intensive tasks: Knowledge retrieval is particularly crucial for knowledge-intensive tasks, such as question answering and fact-based dialogue, where access to accurate and relevant information is essential.
Significance Aspect | Description |
Enhancing LLM's Knowledge Base | Retrieving relevant external knowledge expands the LLM's knowledge base, enabling more accurate and informative outputs. |
Improving Context Understanding | Knowledge retrieval provides additional relevant information, leading to better context understanding and more appropriate responses. |
Mitigating Knowledge Gaps | RAG systems can retrieve up-to-date and domain-specific knowledge, addressing potential knowledge gaps in the LLM's pre-training data. |
Enabling Knowledge-Intensive Tasks | Knowledge retrieval is crucial for tasks that heavily rely on accurate and relevant information, such as question answering and fact-based dialogue. |
Table 2: Significance of knowledge retrieval in RAG systems.
Retrieval Sources and Granularity
The effectiveness of knowledge retrieval in RAG systems heavily depends on the choice of retrieval sources and the granularity at which the retrieval is performed. In this section, we will explore the different types of retrieval sources and discuss the impact of retrieval granularity on the overall performance of RAG systems.
Types of Retrieval Sources
RAG systems can leverage various types of retrieval sources to acquire external knowledge. The most common types include:
Unstructured Data (Text): This includes plain text documents, web pages, and other free-form textual sources. These sources often contain a wealth of information but require advanced techniques for extraction and processing.
Semi-Structured Data (PDF): PDF documents, such as research papers, reports, and manuals, contain a mix of textual and structural information. Extracting knowledge from PDFs requires handling the document structure and formatting.
Structured Data (Knowledge Graphs): Knowledge graphs, such as Wikipedia and Freebase, represent information in a structured and interconnected format. They provide a rich source of factual knowledge that can be efficiently queried and integrated into RAG systems.
LLM-Generated Content: Recent advancements have shown that LLMs themselves can generate high-quality content that can be used as a retrieval source. This approach leverages the knowledge captured within the LLM's parameters to generate relevant information.
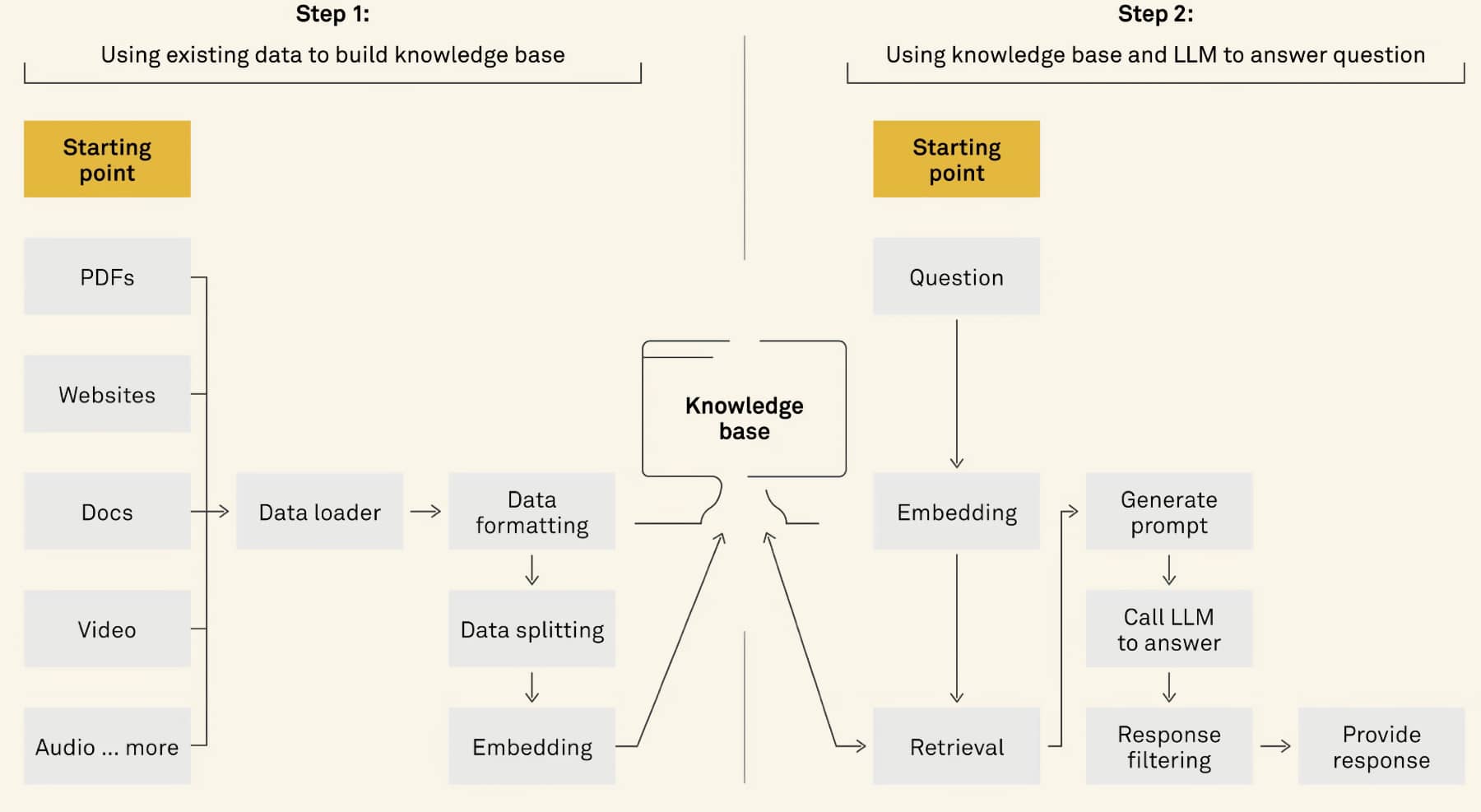
Retrieval Granularity
Retrieval granularity refers to the level at which knowledge is retrieved from the sources. The choice of retrieval granularity can significantly impact the performance and efficiency of RAG systems. Common levels of retrieval granularity include:
Phrase-Level Retrieval: This involves retrieving short phrases or snippets of text that are highly relevant to the query. Phrase-level retrieval can provide precise and targeted information but may lack broader context.
Sentence-Level Retrieval: Sentence-level retrieval focuses on retrieving complete sentences that contain relevant information. It strikes a balance between specificity and context, making it suitable for a wide range of tasks.
Chunk-Level Retrieval: Chunk-level retrieval involves retrieving larger chunks of text, such as paragraphs or sections. It provides more comprehensive information and context but may introduce noise and irrelevant details.
Document-Level Retrieval: Document-level retrieval retrieves entire documents that are relevant to the query. While it offers the most extensive context, it may require additional processing to extract the most pertinent information.
Retrieval Granularity | Pros | Cons |
Phrase-Level | Precise and targeted information | Lacks broader context |
Sentence-Level | Balances specificity and context | May miss important details |
Chunk-Level | Comprehensive information and context | Introduces noise and irrelevant details |
Document-Level | Extensive context | Requires additional processing |
Table 3: Pros and cons of different levels of retrieval granularity.
Impact of Retrieval Source and Granularity on RAG Performance
The choice of retrieval source and granularity can significantly impact the performance of RAG systems. Consider the following factors:
Relevance: The retrieval source should contain information that is highly relevant to the task at hand. Irrelevant or noisy sources can degrade the quality of the generated outputs.
Coverage: The retrieval source should provide sufficient coverage of the topics and domains relevant to the task. Limited coverage can result in knowledge gaps and incomplete information.
Efficiency: The retrieval granularity affects the efficiency of the retrieval process. Fine-grained retrieval (e.g., phrase-level) can be more precise but may require more computational resources, while coarse-grained retrieval (e.g., document-level) can be faster but may introduce noise.
Context: The retrieval granularity determines the amount of context available to the RAG system. Coarse-grained retrieval provides more context but may include irrelevant information, while fine-grained retrieval offers targeted information but may lack broader context.
Balancing these factors and selecting the appropriate retrieval source and granularity based on the specific requirements of the task is crucial for optimal RAG performance.
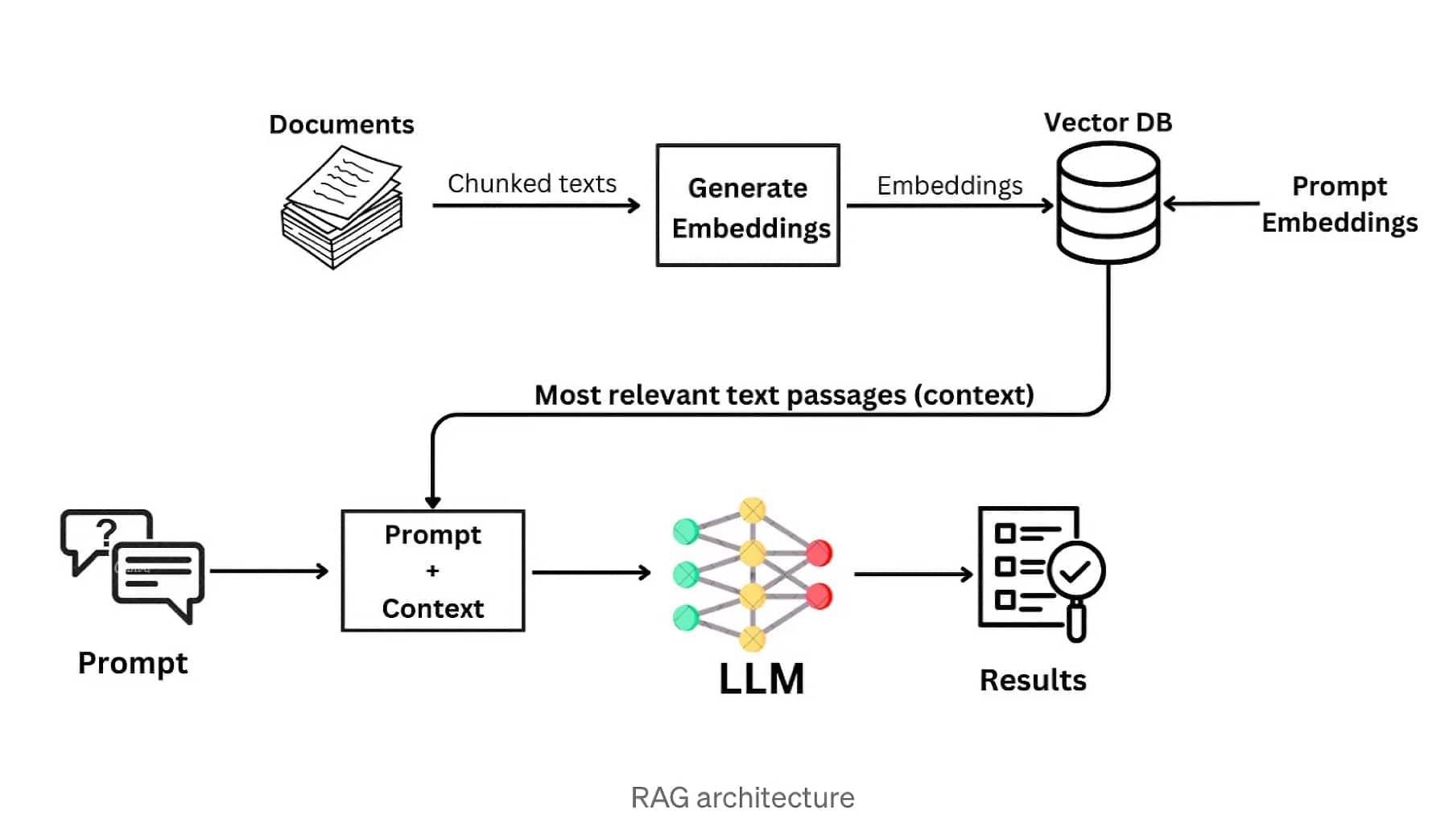
Indexing Optimization Techniques
Efficient and effective knowledge retrieval in RAG systems heavily relies on the indexing process. Indexing involves organizing and storing the external knowledge in a structured format that facilitates fast and accurate retrieval. In this section, we will explore various indexing optimization techniques that can significantly enhance the performance of RAG systems.
Chunking Strategies
Chunking is the process of breaking down large documents or text into smaller, manageable units called chunks. The choice of chunking strategy can greatly impact the retrieval performance and the quality of the generated outputs. Common chunking strategies include:
Fixed-Size Chunking: This strategy involves dividing the text into chunks of a fixed size, such as a specific number of tokens or characters. Fixed-size chunking is simple to implement but may result in chunks that lack semantic coherence.
Sliding Window Approach: The sliding window approach involves moving a fixed-size window over the text, creating overlapping chunks. This approach helps capture the context and relationships between adjacent chunks but may introduce redundancy.
Recursive Splitting: Recursive splitting involves recursively dividing the text into smaller chunks based on semantic or structural boundaries, such as sentences or paragraphs. This strategy aims to preserve the semantic integrity of the chunks but may result in chunks of varying sizes.
Chunking Strategy | Pros | Cons |
Fixed-Size | Simple to implement | May lack semantic coherence |
Sliding Window | Captures context and relationships | Introduces redundancy |
Recursive Splitting | Preserves semantic integrity | Results in chunks of varying sizes |
Table 4: Pros and cons of different chunking strategies.
Metadata Attachments
Attaching metadata to the indexed chunks can provide additional information and improve the retrieval process. Metadata can include various attributes such as the document source, timestamp, author, or topic. There are two main approaches to metadata attachments:
Extracting Metadata from Original Documents: This involves extracting relevant metadata directly from the original documents, such as the title, author, or publication date. Extracting metadata can help filter and prioritize the retrieval results based on specific criteria.
Artificially Constructing Metadata: In some cases, metadata can be artificially constructed to enhance the retrieval process. For example, generating summaries or keywords for each chunk can provide additional context and improve the relevance of the retrieved results.
Metadata attachments can be leveraged during the retrieval process to refine the search results, rank the retrieved chunks, or filter out irrelevant information.
Structural Indexing
Structural indexing involves organizing the indexed chunks in a way that captures the hierarchical or relational structure of the original documents. Two common approaches to structural indexing are:
Hierarchical Index Structures: Hierarchical index structures organize the chunks in a tree-like structure, reflecting the document's hierarchy. This allows for efficient traversal and retrieval of relevant chunks based on their position in the document structure.
Knowledge Graph Indexing: Knowledge graph indexing involves representing the chunks as nodes in a graph and capturing the relationships between them. This approach enables the RAG system to leverage the semantic connections between chunks and perform more advanced reasoning and inference.
Structural indexing techniques can enhance the retrieval process by providing additional context and enabling more sophisticated querying and reasoning capabilities.
By applying these indexing optimization techniques, RAG systems can significantly improve the efficiency and effectiveness of knowledge retrieval. Chunking strategies help break down large documents into manageable units, metadata attachments provide additional context and filtering capabilities, and structural indexing captures the hierarchical and relational structure of the knowledge.
Query Optimization Strategies
Effective knowledge retrieval in RAG systems not only depends on the indexing process but also relies heavily on the formulation and optimization of queries. Query optimization strategies aim to enhance the retrieval performance by improving the relevance and accuracy of the retrieved results. In this section, we will explore various query optimization techniques that can significantly boost the effectiveness of RAG systems.
Query Expansion Techniques
Query expansion involves augmenting the original query with additional relevant terms or phrases to improve the retrieval performance. By expanding the query, the RAG system can capture a wider range of relevant documents and increase the chances of retrieving pertinent information. Common query expansion techniques include:
Multi-Query Expansion: This technique involves generating multiple variations of the original query by incorporating synonyms, related terms, or alternative phrases. The expanded queries are then used to retrieve a broader set of relevant documents.
Sub-Query Generation: Sub-query generation involves breaking down a complex query into smaller, more focused sub-queries. Each sub-query targets a specific aspect or component of the original query, allowing for more precise retrieval of relevant information.
Chain-of-Verification (CoVe): CoVe is a technique that verifies the expanded queries using an LLM to ensure their relevance and coherence. By validating the expanded queries, CoVe helps reduce the retrieval of irrelevant or noisy information.
Query Expansion Technique | Description |
Multi-Query Expansion | Generates multiple variations of the original query using synonyms, related terms, or alternative phrases. |
Sub-Query Generation | Breaks down a complex query into smaller, focused sub-queries targeting specific aspects. |
Chain-of-Verification (CoVe) | Verifies the expanded queries using an LLM to ensure relevance and coherence. |
Table 5: Query expansion techniques for query optimization.
Query Transformation Approaches
Query transformation involves modifying the original query to enhance its effectiveness in retrieving relevant information. By transforming the query, the RAG system can better align the query with the indexed knowledge and improve the retrieval performance. Common query transformation approaches include:
Query Rewriting: Query rewriting involves reformulating the original query to make it more precise, concise, or semantically meaningful. This can be achieved through techniques such as stemming, lemmatization, or semantic parsing.
Hypothesis-Driven Document Retrieval (HyDE): HyDE is a technique that generates a hypothetical answer to the original query and uses it as a basis for retrieving relevant documents. By leveraging the generated hypothesis, HyDE can identify documents that are more likely to contain the desired information.
Step-Back Prompting: Step-back prompting involves generating a high-level, abstract question based on the original query. The step-back question captures the broader context and helps retrieve documents that provide a more comprehensive understanding of the topic.
Query Routing Methods
Query routing involves directing the query to the most appropriate retrieval sources or indexing structures based on its characteristics and requirements. By intelligently routing the queries, the RAG system can optimize the retrieval process and improve the relevance of the retrieved results. Common query routing methods include:
Metadata-Based Routing: Metadata-based routing leverages the metadata attached to the indexed chunks to route the query to the most relevant sources. This can be based on attributes such as the document type, topic, or timestamp.
Semantic Routing: Semantic routing involves analyzing the semantic content of the query and routing it to the indexing structures or retrieval sources that are most likely to contain relevant information. This can be achieved through techniques such as semantic similarity matching or topic modeling.
By employing these query optimization strategies, RAG systems can significantly enhance the retrieval performance and improve the quality of the generated outputs. Query expansion techniques help capture a wider range of relevant documents, query transformation approaches align the query with the indexed knowledge, and query routing methods ensure that the query is directed to the most appropriate retrieval sources.
Embedding Techniques for Knowledge Retrieval
Embedding techniques play a crucial role in knowledge retrieval for RAG systems by capturing the semantic similarity between queries and documents. Embeddings are dense vector representations that encapsulate the meaning and relationships of words, phrases, or documents in a high-dimensional space. By leveraging embedding techniques, RAG systems can effectively measure the relevance of documents to a given query and retrieve the most pertinent information. In this section, we will explore various embedding techniques used in knowledge retrieval for RAG systems.
Dense and Sparse Embeddings
Embeddings can be broadly categorized into two types: dense embeddings and sparse embeddings. Each type has its own characteristics and advantages in the context of knowledge retrieval.
Dense Embeddings: Dense embeddings represent words, phrases, or documents as dense vectors in a continuous vector space. These embeddings are typically learned using neural network architectures, such as Word2Vec or BERT. Dense embeddings capture semantic similarities and can effectively encode the meaning and relationships between words or documents.
Sparse Embeddings: Sparse embeddings, such as TF-IDF or BM25, represent words or documents as high-dimensional sparse vectors. Each dimension corresponds to a specific term or feature, and the value indicates the importance or frequency of that term in the document. Sparse embeddings are computationally efficient and can effectively capture the lexical similarity between queries and documents.
Embedding Type | Characteristics | Advantages |
Dense Embeddings | - Continuous vector space - Learned using neural networks - Capture semantic similarities | - Effective in encoding meaning and relationships - Suitable for capturing semantic relevance |
Sparse Embeddings | - High-dimensional sparse vectors - Term-based representation - Capture lexical similarity | - Computationally efficient - Effective in capturing lexical relevance |
Table 6: Comparison of dense and sparse embeddings.
Hybrid Retrieval Approaches
Hybrid retrieval approaches combine the strengths of both dense and sparse embeddings to enhance the retrieval performance of RAG systems. By leveraging the complementary nature of these embeddings, hybrid approaches can capture both semantic and lexical similarities between queries and documents. Some common hybrid retrieval approaches include:
Late Fusion: Late fusion involves performing separate retrievals using dense and sparse embeddings and then combining the results using ranking or scoring algorithms. This approach allows for the independent optimization of each embedding technique and can improve the overall retrieval performance.
Early Fusion: Early fusion involves concatenating the dense and sparse embeddings into a single representation before performing the retrieval. This approach enables the joint modeling of semantic and lexical similarities and can capture more complex relationships between queries and documents.
Fine-Tuning Embedding Models for Domain-Specific Retrieval
Pre-trained embedding models, such as BERT or Word2Vec, are often trained on large-scale general-domain corpora. However, when working with domain-specific knowledge retrieval tasks, fine-tuning these embedding models on domain-specific data can significantly improve the retrieval performance. Fine-tuning involves adapting the pre-trained embedding models to capture the nuances and terminology specific to the target domain.
By fine-tuning embedding models on domain-specific data, RAG systems can better capture the semantic relationships and similarities within the specific domain, leading to more accurate and relevant retrieval results. This is particularly important in domains with specialized vocabularies, such as healthcare, finance, or legal domains.
Leveraging Adapters for Retrieval Optimization
Adapters are lightweight neural network modules that can be plugged into pre-trained embedding models to adapt them for specific tasks or domains. By leveraging adapters, RAG systems can efficiently optimize the embedding models for knowledge retrieval without the need for full fine-tuning.
Adapters allow for the selective adaptation of specific layers or components of the embedding model while keeping the majority of the model parameters fixed. This approach reduces the computational cost and enables faster adaptation to new retrieval tasks or domains.
By employing these embedding techniques, RAG systems can effectively capture the semantic and lexical similarities between queries and documents, leading to improved retrieval performance and more relevant results. Hybrid retrieval approaches combine the strengths of dense and sparse embeddings, fine-tuning embedding models enables domain-specific optimization, and adapters provide an efficient way to adapt embedding models for specific retrieval tasks.
Challenges and Considerations in Knowledge Retrieval for RAG
While knowledge retrieval plays a crucial role in the effectiveness of RAG systems, it also presents several challenges and considerations that need to be addressed. These challenges encompass various aspects, including data format and structure, retrieval precision and recall, noise and irrelevance, and scalability and efficiency. In this section, we will explore these challenges in detail and discuss potential strategies to mitigate them.
Handling Diverse Data Formats and Structures
One of the primary challenges in knowledge retrieval for RAG systems is dealing with the diversity of data formats and structures. External knowledge sources can come in various forms, such as unstructured text, semi-structured documents (e.g., PDFs), and structured data (e.g., knowledge graphs). Each format requires different preprocessing, parsing, and indexing techniques to extract and represent the relevant information effectively.
To handle diverse data formats, RAG systems need to incorporate robust data ingestion pipelines that can process and normalize the input data into a consistent representation. This may involve techniques such as text extraction, structure parsing, and entity recognition. Additionally, developing flexible indexing schemes that can accommodate different data structures is crucial for efficient retrieval.
Balancing Retrieval Precision and Recall
Another significant challenge in knowledge retrieval is striking the right balance between retrieval precision and recall. Precision refers to the relevance of the retrieved documents to the query, while recall measures the completeness of the retrieved results in covering all relevant information.
High precision ensures that the retrieved documents are highly relevant to the query, reducing noise and irrelevant information. However, focusing solely on precision may lead to missing important information and limited coverage. On the other hand, optimizing for high recall guarantees comprehensive coverage but may introduce more irrelevant documents.
To balance precision and recall, RAG systems can employ techniques such as relevance scoring, ranking algorithms, and filtering mechanisms. These techniques help prioritize the most relevant documents while maintaining adequate coverage. Additionally, incorporating user feedback and iterative refinement can further improve the retrieval performance.
Dealing with Noise and Irrelevant Information
Knowledge retrieval often encounters the challenge of dealing with noise and irrelevant information in the retrieved documents. Noisy data can arise from various sources, such as data quality issues, preprocessing errors, or the presence of unrelated content within the documents.
Irrelevant information can negatively impact the performance of RAG systems by introducing misleading or distracting content that hinders the generation of accurate and coherent responses. It can also increase the computational overhead and slow down the retrieval process.
To mitigate noise and irrelevance, RAG systems can employ techniques such as data cleaning, filtering, and denoising. These techniques aim to identify and remove or suppress irrelevant or low-quality information from the retrieved documents. Additionally, incorporating relevance feedback mechanisms and user interaction can help refine the retrieval results and improve the signal-to-noise ratio.
Scalability and Efficiency of Retrieval Systems
As the volume of external knowledge sources continues to grow, scalability and efficiency become critical considerations in knowledge retrieval for RAG systems. Retrieving relevant information from large-scale datasets in real-time poses significant computational challenges.
Efficient indexing structures and retrieval algorithms are essential to enable fast and scalable retrieval. Techniques such as inverted indexing, distributed indexing, and caching can help optimize the retrieval process and reduce latency. Additionally, employing parallel processing and distributed computing frameworks can further enhance the scalability of the retrieval system.
Another aspect of scalability is the ability to handle incremental updates and new knowledge acquisition. RAG systems should be designed to efficiently incorporate new information into the existing knowledge base without requiring complete re-indexing or retraining.
Challenge | Considerations | Potential Strategies |
Data Format Diversity | - Preprocessing and parsing - Flexible indexing schemes | - Robust data ingestion pipelines - Normalization techniques |
Precision vs. Recall | - Relevance scoring - Ranking algorithms - Filtering mechanisms | - Balancing techniques - User feedback and refinement |
Noise and Irrelevance | - Data cleaning - Filtering and denoising | - Relevance feedback - User interaction |
Scalability and Efficiency | - Indexing structures - Retrieval algorithms - Parallel processing | - Inverted indexing - Distributed computing - Incremental updates |
Table 7: Challenges, considerations, and potential strategies in knowledge retrieval for RAG.
Addressing these challenges requires a combination of advanced techniques, carefully designed architectures, and continuous optimization based on user feedback and system performance. By tackling these challenges head-on, RAG systems can ensure effective and efficient knowledge retrieval, enabling them to generate high-quality and contextually relevant responses.
In the next section, we will explore the future directions and opportunities in knowledge retrieval for RAG systems, highlighting the emerging trends and potential areas for further research and development.
Future Directions and Opportunities
The field of knowledge retrieval for RAG systems is constantly evolving, driven by advancements in natural language processing, machine learning, and information retrieval techniques. As research progresses, several promising future directions and opportunities emerge, offering the potential to further enhance the effectiveness and applicability of RAG systems. In this section, we will explore these future directions and highlight the areas where significant improvements and innovations can be made.
Integrating Advanced Retrieval Techniques
One promising direction for future research is the integration of advanced retrieval techniques into RAG systems. These techniques aim to improve the precision, relevance, and efficiency of knowledge retrieval. Some notable advanced retrieval techniques include:
Semantic Retrieval: Semantic retrieval techniques focus on capturing the underlying meaning and intent behind the queries and documents. By leveraging deep learning models and semantic representations, such as word embeddings or knowledge graphs, semantic retrieval can enhance the understanding of the query and improve the relevance of the retrieved documents.
Multi-Hop Retrieval: Multi-hop retrieval involves retrieving information across multiple levels of granularity or through a series of connected documents. This technique enables RAG systems to capture more complex relationships and gather information from different sources to provide a more comprehensive response. Multi-hop retrieval can be particularly useful in scenarios that require reasoning or inferencing across multiple pieces of evidence.
Exploiting Knowledge Graphs for Enhanced Retrieval
Knowledge graphs have emerged as a powerful way to represent and store structured knowledge. They capture entities, relationships, and attributes in a graph-based format, enabling efficient querying and reasoning. Exploiting knowledge graphs for enhanced retrieval in RAG systems offers several benefits:
Entity-Aware Retrieval: By leveraging the entity information stored in knowledge graphs, RAG systems can perform entity-aware retrieval. This involves identifying and disambiguating entities in the queries and documents, enabling more precise and targeted retrieval based on the relevant entities and their relationships.
Graph-Based Reasoning: Knowledge graphs enable graph-based reasoning techniques, such as path finding and graph traversal, to infer new knowledge and discover implicit connections between entities. RAG systems can exploit these reasoning capabilities to retrieve more comprehensive and contextually relevant information.
Leveraging Self-Supervised Learning for Retrieval Optimization
Self-supervised learning has shown significant promise in various natural language processing tasks, including language modeling and representation learning. In the context of knowledge retrieval for RAG systems, self-supervised learning can be leveraged to optimize the retrieval process:
Retrieval-Augmented Language Modeling: By incorporating retrieval components into the language modeling process, RAG systems can learn to retrieve relevant information without explicit supervision. This approach enables the model to learn retrieval strategies that are optimized for the specific language generation task.
Unsupervised Retrieval Adaptation: Self-supervised learning techniques can be employed to adapt the retrieval process to new domains or tasks without the need for labeled data. By leveraging unsupervised objectives, such as contrastive learning or masked language modeling, RAG systems can learn domain-specific retrieval patterns and improve the relevance of the retrieved documents.
Developing Standardized Evaluation Metrics for Knowledge Retrieval in RAG
Evaluating the effectiveness of knowledge retrieval in RAG systems is crucial for assessing their performance and driving further improvements. However, the lack of standardized evaluation metrics poses challenges in comparing and benchmarking different approaches. Developing standardized evaluation metrics specifically tailored for knowledge retrieval in RAG systems is an important future direction.
These evaluation metrics should consider various aspects, such as the relevance of the retrieved documents, the coverage of the relevant information, and the impact on the quality of the generated responses. Additionally, establishing benchmark datasets and evaluation protocols can facilitate fair comparisons and promote reproducibility in the field.
Future Direction | Key Aspects | Potential Impact |
Advanced Retrieval Techniques | - Semantic retrieval - Multi-hop retrieval | - Improved precision and relevance - Capturing complex relationships |
Knowledge Graph Exploitation | - Entity-aware retrieval - Graph-based reasoning | - Enhanced entity understanding - Inferencing and knowledge discovery |
Self-Supervised Learning | - Retrieval-augmented language modeling - Unsupervised retrieval adaptation | - Optimized retrieval strategies - Domain adaptation without labeled data |
Standardized Evaluation Metrics | - Relevance assessment - Coverage evaluation - Response quality impact | - Fair comparisons and benchmarking - Reproducibility and standardization |
Table 8: Future directions, key aspects, and potential impact in knowledge retrieval for RAG.
By pursuing these future directions and opportunities, researchers and practitioners can unlock the full potential of knowledge retrieval in RAG systems. Integrating advanced retrieval techniques, exploiting knowledge graphs, leveraging self-supervised learning, and developing standardized evaluation metrics will pave the way for more effective, efficient, and robust RAG systems that can generate high-quality and contextually relevant responses across a wide range of domains and applications.
Unlocking the Power of Knowledge Retrieval in RAG Systems
In this comprehensive exploration of the role of knowledge retrieval in Retrieval-Augmented Generation (RAG) systems, we have unveiled the critical importance of effective and efficient retrieval mechanisms in enhancing the capabilities of large language models. By seamlessly integrating external knowledge sources, RAG systems can overcome the limitations of static parametric knowledge and generate more accurate, informative, and contextually relevant responses.
Throughout this article, we have delved into the intricacies of knowledge retrieval, examining its key components, such as indexing, querying, and retrieval, and highlighting their significance in the overall RAG pipeline. We have explored various techniques and strategies to optimize the retrieval process, including indexing optimization, query optimization, and embedding techniques, which collectively contribute to improved retrieval performance and result relevance.
Moreover, we have addressed the challenges and considerations associated with knowledge retrieval in RAG systems, such as handling diverse data formats, balancing precision and recall, dealing with noise and irrelevance, and ensuring scalability and efficiency. By tackling these challenges head-on and leveraging advanced techniques and architectures, RAG systems can unlock the true potential of knowledge retrieval and deliver superior performance across a wide range of applications.
As we look towards the future, the field of knowledge retrieval in RAG systems presents exciting opportunities for further research and development. The integration of advanced retrieval techniques, such as semantic retrieval and multi-hop retrieval, holds promise for capturing more complex relationships and improving the relevance of retrieved information. Exploiting knowledge graphs and leveraging self-supervised learning techniques can further enhance the understanding and adaptation of retrieval processes to specific domains and tasks.
Furthermore, the development of standardized evaluation metrics and benchmarks for knowledge retrieval in RAG systems is crucial for driving progress and facilitating fair comparisons among different approaches. By establishing clear evaluation criteria and protocols, researchers and practitioners can effectively assess the performance of RAG systems and identify areas for improvement.
In conclusion, the power of knowledge retrieval in RAG systems lies in its ability to bridge the gap between the vast amounts of external knowledge and the generative capabilities of large language models. By harnessing the potential of effective and efficient retrieval mechanisms, RAG systems can unlock new frontiers in natural language processing, enabling more intelligent, knowledgeable, and context-aware AI systems. As research in this field continues to advance, we can anticipate the emergence of RAG systems that can truly revolutionize the way we interact with and benefit from artificial intelligence in our daily lives.

